

前端开发
jQuery报错Uncaught TypeError: a.indexOf is not a function 怎么处理?
回复前端开发 • zkbhj 回复了问题 • 1 人关注 • 1 个回复 • 5093 次浏览 • 2020-02-29 12:04
理解HTTP请求头中的参数:If-Modified-Since与Last-Modified
专业名词 • zkbhj 发表了文章 • 0 个评论 • 2408 次浏览 • 2020-01-17 10:25
Last-Modified 与If-Modified-Since 都是标准的HTTP请求头标签,用于记录页面的最后修改时间。
2.发送方向
Last-Modified 是由服务器发送给客户端的HTTP请求头标签
If-Modified-Since 则是由客户端发送给服务器的HTTP请求头标签
3.应用场景
(1)Last-Modified
在浏览器第一次请求某一个URL时,服务器端的返回状态会是200,内容是你请求的资源,同时有一个Last-Modified的属性标记此文件在服务期端最后被修改的时间,格式类似这样:
Last-Modified: Fri, 12 May 2006 18:53:33 GMT
后面跟的时间是服务器存储的文件修改时间
(2)If-Modified-Since
客户端第二次请求此URL时,根据 HTTP 协议的规定,浏览器会向服务器传送 If-Modified-Since 报头,询问该时间之后文件是否有被修改过:
If-Modified-Since: Fri, 12 May 2006 18:53:33 GMT
后面跟的时间是本地浏览器存储的文件修改时间
如果服务器端的资源没有变化,则时间一致,自动返回HTTP状态码304(Not Changed.)状态码,内容为空,客户端接到之后,就直接把本地缓存文件显示到浏览器中,这样就节省了传输数据量。
如果服务器端资源发生改变或者重启服务器时,时间不一致,就返回HTTP状态码200和新的文件内容,客户端接到之后,会丢弃旧文件,把新文件缓存起来,并显示到浏览器中。
以上操作可以保证不向客户端重复发出资源,也保证当服务器有变化时,客户端能够得到最新的资源。
————————————————
版权声明:本文为CSDN博主「上善若海」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lhl11242 ... 67764 查看全部
Last-Modified 与If-Modified-Since 都是标准的HTTP请求头标签,用于记录页面的最后修改时间。
2.发送方向
Last-Modified 是由服务器发送给客户端的HTTP请求头标签
If-Modified-Since 则是由客户端发送给服务器的HTTP请求头标签
3.应用场景
(1)Last-Modified
在浏览器第一次请求某一个URL时,服务器端的返回状态会是200,内容是你请求的资源,同时有一个Last-Modified的属性标记此文件在服务期端最后被修改的时间,格式类似这样:
Last-Modified: Fri, 12 May 2006 18:53:33 GMT
后面跟的时间是服务器存储的文件修改时间
(2)If-Modified-Since
客户端第二次请求此URL时,根据 HTTP 协议的规定,浏览器会向服务器传送 If-Modified-Since 报头,询问该时间之后文件是否有被修改过:
If-Modified-Since: Fri, 12 May 2006 18:53:33 GMT
后面跟的时间是本地浏览器存储的文件修改时间
如果服务器端的资源没有变化,则时间一致,自动返回HTTP状态码304(Not Changed.)状态码,内容为空,客户端接到之后,就直接把本地缓存文件显示到浏览器中,这样就节省了传输数据量。
如果服务器端资源发生改变或者重启服务器时,时间不一致,就返回HTTP状态码200和新的文件内容,客户端接到之后,会丢弃旧文件,把新文件缓存起来,并显示到浏览器中。
以上操作可以保证不向客户端重复发出资源,也保证当服务器有变化时,客户端能够得到最新的资源。
————————————————
版权声明:本文为CSDN博主「上善若海」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lhl11242 ... 67764
JWT:完全前后端分离的项目如何做用户身份验证更安全?看这篇就够了!
前端开发 • zkbhj 发表了文章 • 0 个评论 • 4711 次浏览 • 2018-09-19 14:48
传统方式
前后端分离通过Restful API进行数据交互时,如何验证用户的登录信息及权限。在原来的项目中,使用的是最传统也是最简单的方式,前端登录,后端根据用户信息生成一个token,并保存这个 token 和对应的用户id到数据库或Session中,接着把 token 传给用户,存入浏览器 cookie,之后浏览器请求带上这个cookie,后端根据这个cookie值来查询用户,验证是否过期。
但这样做问题就很多,如果我们的页面出现了 XSS 漏洞,由于 cookie 可以被 JavaScript 读取,XSS 漏洞会导致用户 token 泄露,而作为后端识别用户的标识,cookie 的泄露意味着用户信息不再安全。尽管我们通过转义输出内容,使用 CDN 等可以尽量避免 XSS 注入,但谁也不能保证在大型的项目中不会出现这个问题。
在设置 cookie 的时候,其实你还可以设置 httpOnly 以及 secure 项。设置 httpOnly 后 cookie 将不能被 JS 读取,浏览器会自动的把它加在请求的 header 当中,设置 secure 的话,cookie 就只允许通过 HTTPS 传输。secure 选项可以过滤掉一些使用 HTTP 协议的 XSS 注入,但并不能完全阻止。
httpOnly 选项使得 JS 不能读取到 cookie,那么 XSS 注入的问题也基本不用担心了。但设置 httpOnly 就带来了另一个问题,就是很容易的被 XSRF,即跨站请求伪造。当你浏览器开着这个页面的时候,另一个页面可以很容易的跨站请求这个页面的内容。因为 cookie 默认被发了出去。
另外,如果将验证信息保存在数据库中,后端每次都需要根据token查出用户id,这就增加了数据库的查询和存储开销。若把验证信息保存在session中,有加大了服务器端的存储压力。那我们可不可以不要服务器去查询呢?如果我们生成token遵循一定的规律,比如我们使用对称加密算法来加密用户id形成token,那么服务端以后其实只要解密该token就可以知道用户的id是什么了。不过呢,我只是举个例子而已,要是真这么做,只要你的对称加密算法泄露了,其他人可以通过这种加密方式进行伪造token,那么所有用户信息都不再安全了。恩,那用非对称加密算法来做呢,其实现在有个规范就是这样做的,就是我们接下来要介绍的 JWT。
Json Web Token(JWT)
JWT 是一个开放标准(RFC 7519),它定义了一种用于简洁,自包含的用于通信双方之间以 JSON 对象的形式安全传递信息的方法。JWT 可以使用 HMAC 算法或者是 RSA 的公钥密钥对进行签名。它具备两个特点:
简洁(Compact)
可以通过URL, POST 参数或者在 HTTP header 发送,因为数据量小,传输速度快
自包含(Self-contained)
负载中包含了所有用户所需要的信息,避免了多次查询数据库
JWT 组成
Header 头部
头部包含了两部分,token 类型和采用的加密算法
{
"alg": "HS256",
"typ": "JWT"
}它会使用 Base64 编码组成 JWT 结构的第一部分,如果你使用Node.js,可以用Node.js的包base64url来得到这个字符串。
Base64是一种编码,也就是说,它是可以被翻译回原来的样子来的。它并不是一种加密过程。
Payload 负载
这部分就是我们存放信息的地方了,你可以把用户 ID 等信息放在这里,JWT 规范里面对这部分有进行了比较详细的介绍,常用的由 iss(签发者),exp(过期时间),sub(面向的用户),aud(接收方),iat(签发时间)。
{
"iss": "lion1ou JWT",
"iat": 1441593502,
"exp": 1441594722,
"aud": "www.example.com",
"sub": "lion1ou@163.com"
}同样的,它会使用 Base64 编码组成 JWT 结构的第二部分
Signature 签名
前面两部分都是使用 Base64 进行编码的,即前端可以解开知道里面的信息。Signature 需要使用编码后的 header 和 payload 以及我们提供的一个密钥,然后使用 header 中指定的签名算法(HS256)进行签名。签名的作用是保证 JWT 没有被篡改过。
三个部分通过.连接在一起就是我们的 JWT 了,它可能长这个样子,长度貌似和你的加密算法和私钥有关系。eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6IjU3ZmVmMTY0ZTU0YWY2NGZmYzUzZGJkNSIsInhzcmYiOiI0ZWE1YzUwOGE2NTY2ZTc2MjQwNTQzZjhmZWIwNmZkNDU3Nzc3YmUzOTU0OWM0MDE2NDM2YWZkYTY1ZDIzMzBlIiwiaWF0IjoxNDc2NDI3OTMzfQ.PA3QjeyZSUh7H0GfE0vJaKW4LjKJuC3dVLQiY4hii8s
其实到这一步可能就有人会想了,HTTP 请求总会带上 token,这样这个 token 传来传去占用不必要的带宽啊。如果你这么想了,那你可以去了解下 HTTP2,HTTP2 对头部进行了压缩,相信也解决了这个问题。
签名的目的
最后一步签名的过程,实际上是对头部以及负载内容进行签名,防止内容被窜改。如果有人对头部以及负载的内容解码之后进行修改,再进行编码,最后加上之前的签名组合形成新的JWT的话,那么服务器端会判断出新的头部和负载形成的签名和JWT附带上的签名是不一样的。如果要对新的头部和负载进行签名,在不知道服务器加密时用的密钥的话,得出来的签名也是不一样的。
信息暴露
在这里大家一定会问一个问题:Base64是一种编码,是可逆的,那么我的信息不就被暴露了吗?
是的。所以,在JWT中,不应该在负载里面加入任何敏感的数据。在上面的例子中,我们传输的是用户的User ID。这个值实际上不是什么敏感内容,一般情况下被知道也是安全的。但是像密码这样的内容就不能被放在JWT中了。如果将用户的密码放在了JWT中,那么怀有恶意的第三方通过Base64解码就能很快地知道你的密码了。
因此JWT适合用于向Web应用传递一些非敏感信息。JWT还经常用于设计用户认证和授权系统,甚至实现Web应用的单点登录。
JWT 使用
首先,前端通过Web表单将自己的用户名和密码发送到后端的接口。这一过程一般是一个HTTP POST请求。建议的方式是通过SSL加密的传输(https协议),从而避免敏感信息被嗅探。后端核对用户名和密码成功后,将用户的id等其他信息作为JWT Payload(负载),将其与头部分别进行Base64编码拼接后签名,形成一个JWT。形成的JWT就是一个形同lll.zzz.xxx的字符串。后端将JWT字符串作为登录成功的返回结果返回给前端。前端可以将返回的结果保存在localStorage或sessionStorage上,退出登录时前端删除保存的JWT即可。前端在每次请求时将JWT放入HTTP Header中的Authorization位。(解决XSS和XSRF问题)后端检查是否存在,如存在验证JWT的有效性。例如,检查签名是否正确;检查Token是否过期;检查Token的接收方是否是自己(可选)。验证通过后后端使用JWT中包含的用户信息进行其他逻辑操作,返回相应结果。
和Session方式存储id的差异
Session方式存储用户id的最大弊病在于Session是存储在服务器端的,所以需要占用大量服务器内存,对于较大型应用而言可能还要保存许多的状态。一般而言,大型应用还需要借助一些KV数据库和一系列缓存机制来实现Session的存储。
而JWT方式将用户状态分散到了客户端中,可以明显减轻服务端的内存压力。除了用户id之外,还可以存储其他的和用户相关的信息,例如该用户是否是管理员、用户所在的分组等。虽说JWT方式让服务器有一些计算压力(例如加密、编码和解码),但是这些压力相比磁盘存储而言可能就不算什么了。具体是否采用,需要在不同场景下用数据说话。
单点登录
Session方式来存储用户id,一开始用户的Session只会存储在一台服务器上。对于有多个子域名的站点,每个子域名至少会对应一台不同的服务器,例如:www.taobao.com,nv.taobao.com,nz.taobao.com,login.taobao.com。所以如果要实现在login.taobao.com登录后,在其他的子域名下依然可以取到Session,这要求我们在多台服务器上同步Session。使用JWT的方式则没有这个问题的存在,因为用户的状态已经被传送到了客户端。
总结
JWT的主要作用在于(一)可附带用户信息,后端直接通过JWT获取相关信息。(二)使用本地保存,通过HTTP Header中的Authorization位提交验证。但其实关于JWT存放到哪里一直有很多讨论,有人说存放到本地存储,有人说存 cookie。个人偏向于放在本地存储,如果你有什么意见和看法欢迎提出。
参考文档:
https://segmentfault.com/a/1190000005783306
https://ruiming.me/authentication-of-frontend-backend-separate-application/
总结和摘录自:
https://blog.csdn.net/kevin_lc ... 46723 查看全部
传统方式
前后端分离通过Restful API进行数据交互时,如何验证用户的登录信息及权限。在原来的项目中,使用的是最传统也是最简单的方式,前端登录,后端根据用户信息生成一个token,并保存这个 token 和对应的用户id到数据库或Session中,接着把 token 传给用户,存入浏览器 cookie,之后浏览器请求带上这个cookie,后端根据这个cookie值来查询用户,验证是否过期。
但这样做问题就很多,如果我们的页面出现了 XSS 漏洞,由于 cookie 可以被 JavaScript 读取,XSS 漏洞会导致用户 token 泄露,而作为后端识别用户的标识,cookie 的泄露意味着用户信息不再安全。尽管我们通过转义输出内容,使用 CDN 等可以尽量避免 XSS 注入,但谁也不能保证在大型的项目中不会出现这个问题。
在设置 cookie 的时候,其实你还可以设置 httpOnly 以及 secure 项。设置 httpOnly 后 cookie 将不能被 JS 读取,浏览器会自动的把它加在请求的 header 当中,设置 secure 的话,cookie 就只允许通过 HTTPS 传输。secure 选项可以过滤掉一些使用 HTTP 协议的 XSS 注入,但并不能完全阻止。
httpOnly 选项使得 JS 不能读取到 cookie,那么 XSS 注入的问题也基本不用担心了。但设置 httpOnly 就带来了另一个问题,就是很容易的被 XSRF,即跨站请求伪造。当你浏览器开着这个页面的时候,另一个页面可以很容易的跨站请求这个页面的内容。因为 cookie 默认被发了出去。
另外,如果将验证信息保存在数据库中,后端每次都需要根据token查出用户id,这就增加了数据库的查询和存储开销。若把验证信息保存在session中,有加大了服务器端的存储压力。那我们可不可以不要服务器去查询呢?如果我们生成token遵循一定的规律,比如我们使用对称加密算法来加密用户id形成token,那么服务端以后其实只要解密该token就可以知道用户的id是什么了。不过呢,我只是举个例子而已,要是真这么做,只要你的对称加密算法泄露了,其他人可以通过这种加密方式进行伪造token,那么所有用户信息都不再安全了。恩,那用非对称加密算法来做呢,其实现在有个规范就是这样做的,就是我们接下来要介绍的 JWT。
Json Web Token(JWT)
JWT 是一个开放标准(RFC 7519),它定义了一种用于简洁,自包含的用于通信双方之间以 JSON 对象的形式安全传递信息的方法。JWT 可以使用 HMAC 算法或者是 RSA 的公钥密钥对进行签名。它具备两个特点:
简洁(Compact)
可以通过URL, POST 参数或者在 HTTP header 发送,因为数据量小,传输速度快
自包含(Self-contained)
负载中包含了所有用户所需要的信息,避免了多次查询数据库
JWT 组成

Header 头部
头部包含了两部分,token 类型和采用的加密算法
{
"alg": "HS256",
"typ": "JWT"
}它会使用 Base64 编码组成 JWT 结构的第一部分,如果你使用Node.js,可以用Node.js的包base64url来得到这个字符串。
Base64是一种编码,也就是说,它是可以被翻译回原来的样子来的。它并不是一种加密过程。
Payload 负载
这部分就是我们存放信息的地方了,你可以把用户 ID 等信息放在这里,JWT 规范里面对这部分有进行了比较详细的介绍,常用的由 iss(签发者),exp(过期时间),sub(面向的用户),aud(接收方),iat(签发时间)。
{
"iss": "lion1ou JWT",
"iat": 1441593502,
"exp": 1441594722,
"aud": "www.example.com",
"sub": "lion1ou@163.com"
}同样的,它会使用 Base64 编码组成 JWT 结构的第二部分Signature 签名
前面两部分都是使用 Base64 进行编码的,即前端可以解开知道里面的信息。Signature 需要使用编码后的 header 和 payload 以及我们提供的一个密钥,然后使用 header 中指定的签名算法(HS256)进行签名。签名的作用是保证 JWT 没有被篡改过。
三个部分通过.连接在一起就是我们的 JWT 了,它可能长这个样子,长度貌似和你的加密算法和私钥有关系。
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6IjU3ZmVmMTY0ZTU0YWY2NGZmYzUzZGJkNSIsInhzcmYiOiI0ZWE1YzUwOGE2NTY2ZTc2MjQwNTQzZjhmZWIwNmZkNDU3Nzc3YmUzOTU0OWM0MDE2NDM2YWZkYTY1ZDIzMzBlIiwiaWF0IjoxNDc2NDI3OTMzfQ.PA3QjeyZSUh7H0GfE0vJaKW4LjKJuC3dVLQiY4hii8s其实到这一步可能就有人会想了,HTTP 请求总会带上 token,这样这个 token 传来传去占用不必要的带宽啊。如果你这么想了,那你可以去了解下 HTTP2,HTTP2 对头部进行了压缩,相信也解决了这个问题。
签名的目的
最后一步签名的过程,实际上是对头部以及负载内容进行签名,防止内容被窜改。如果有人对头部以及负载的内容解码之后进行修改,再进行编码,最后加上之前的签名组合形成新的JWT的话,那么服务器端会判断出新的头部和负载形成的签名和JWT附带上的签名是不一样的。如果要对新的头部和负载进行签名,在不知道服务器加密时用的密钥的话,得出来的签名也是不一样的。
信息暴露
在这里大家一定会问一个问题:Base64是一种编码,是可逆的,那么我的信息不就被暴露了吗?
是的。所以,在JWT中,不应该在负载里面加入任何敏感的数据。在上面的例子中,我们传输的是用户的User ID。这个值实际上不是什么敏感内容,一般情况下被知道也是安全的。但是像密码这样的内容就不能被放在JWT中了。如果将用户的密码放在了JWT中,那么怀有恶意的第三方通过Base64解码就能很快地知道你的密码了。
因此JWT适合用于向Web应用传递一些非敏感信息。JWT还经常用于设计用户认证和授权系统,甚至实现Web应用的单点登录。
JWT 使用

- 首先,前端通过Web表单将自己的用户名和密码发送到后端的接口。这一过程一般是一个HTTP POST请求。建议的方式是通过SSL加密的传输(https协议),从而避免敏感信息被嗅探。
- 后端核对用户名和密码成功后,将用户的id等其他信息作为JWT Payload(负载),将其与头部分别进行Base64编码拼接后签名,形成一个JWT。形成的JWT就是一个形同lll.zzz.xxx的字符串。
- 后端将JWT字符串作为登录成功的返回结果返回给前端。前端可以将返回的结果保存在localStorage或sessionStorage上,退出登录时前端删除保存的JWT即可。
- 前端在每次请求时将JWT放入HTTP Header中的Authorization位。(解决XSS和XSRF问题)
- 后端检查是否存在,如存在验证JWT的有效性。例如,检查签名是否正确;检查Token是否过期;检查Token的接收方是否是自己(可选)。
- 验证通过后后端使用JWT中包含的用户信息进行其他逻辑操作,返回相应结果。
和Session方式存储id的差异
Session方式存储用户id的最大弊病在于Session是存储在服务器端的,所以需要占用大量服务器内存,对于较大型应用而言可能还要保存许多的状态。一般而言,大型应用还需要借助一些KV数据库和一系列缓存机制来实现Session的存储。
而JWT方式将用户状态分散到了客户端中,可以明显减轻服务端的内存压力。除了用户id之外,还可以存储其他的和用户相关的信息,例如该用户是否是管理员、用户所在的分组等。虽说JWT方式让服务器有一些计算压力(例如加密、编码和解码),但是这些压力相比磁盘存储而言可能就不算什么了。具体是否采用,需要在不同场景下用数据说话。
单点登录
Session方式来存储用户id,一开始用户的Session只会存储在一台服务器上。对于有多个子域名的站点,每个子域名至少会对应一台不同的服务器,例如:www.taobao.com,nv.taobao.com,nz.taobao.com,login.taobao.com。所以如果要实现在login.taobao.com登录后,在其他的子域名下依然可以取到Session,这要求我们在多台服务器上同步Session。使用JWT的方式则没有这个问题的存在,因为用户的状态已经被传送到了客户端。
总结
JWT的主要作用在于(一)可附带用户信息,后端直接通过JWT获取相关信息。(二)使用本地保存,通过HTTP Header中的Authorization位提交验证。但其实关于JWT存放到哪里一直有很多讨论,有人说存放到本地存储,有人说存 cookie。个人偏向于放在本地存储,如果你有什么意见和看法欢迎提出。
参考文档:
https://segmentfault.com/a/1190000005783306
https://ruiming.me/authentication-of-frontend-backend-separate-application/
总结和摘录自:
https://blog.csdn.net/kevin_lc ... 46723
父页面parent.html <html>
<head>
<script type="text/javascript">
function say(){
alert("parent.html");
}
function callChild(){
myFrame.window.say();
myFrame.window.document.getElementById("button").value="调用结束";
}
</script>
</head>
<body>
<input id="button" type="button" value="调用child.html中的函数say()" onclick="callChild()"/>
<iframe name="myFrame" src="child.html"></iframe>
</body>
</html>
子页面child.html
<html>
<head>
<script type="text/javascript">
function say(){
alert("child.html");
}
function callParent(){
parent.say();
parent.window.document.getElementById("button").value="调用结束";
}
</script>
</head>
<body>
<input id="button" type="button" value="调用parent.html中的say()函数" onclick="callParent()"/>
</body>
</html>
方法调用
父页面调用子页面方法:FrameName.window.childMethod();
子页面调用父页面方法:parent.window.parentMethod();
DOM元素访问
获取到页面的window.document对象后,即可访问DOM元素
注意事项
要确保在iframe加载完成后再进行操作,如果iframe还未加载完成就开始调用里面的方法或变量,会产生错误。判断iframe是否加载完成有两种方法:
1. iframe上用onload事件
2. 用document.readyState=="complete"来判断
二、跨域父子页面通信方法
如果iframe所链接的是外部页面,因为安全机制就不能使用同域名下的通信方式了。
父页面向子页面传递数据
实现的技巧是利用location对象的hash值,通过它传递通信数据。在父页面设置iframe的src后面多加个data字符串,然后在子页面中通过某种方式能即时的获取到这儿的data就可以了,例如:
1. 在子页面中通过setInterval方法设置定时器,监听location.href的变化即可获得上面的data信息
2. 然后子页面根据这个data信息进行相应的逻辑处理
子页面向父页面传递数据
实现技巧就是利用一个代理iframe,它嵌入到子页面中,并且和父页面必须保持是同域,然后通过它充分利用上面第一种通信方式的实现原理就把子页面的数据传递给代理iframe,然后由于代理的iframe和主页面是同域的,所以主页面就可以利用同域的方式获取到这些数据。使用 window.top或者window.parent.parent获取浏览器最顶层window对象的引用。
由此可以看出来吧。它就是表示一个来源。看下图的一个请求的 Referer 信息。
Referer 的正确英语拼法是referrer 。由于早期HTTP规范的拼写错误,为了保持向后兼容就将错就错了。其它网络技术的规范企图修正此问题,使用正确拼法,所以目前拼法不统一。还有它第一个字母是大写。
Referer的作用?
1.防盗链。
刚刚前面有提到一个小 Demo 。
我在www.google.com里有一个www.baidu.com链接,那么点击这个www.baidu.com,它的header信息里就有: Referer=http://www.google.com
那么可以利用这个来防止盗链了,比如我只允许我自己的网站访问我自己的图片服务器,那我的域名是www.google.com,那么图片服务器每次取到Referer来判断一下是不是我自己的域名www.google.com,如果是就继续访问,不是就拦截。
这是不是就达到防盗链的效果了?
将这个http请求发给服务器后,如果服务器要求必须是某个地址或者某几个地址才能访问,而你发送的referer不符合他的要求,就会拦截或者跳转到他要求的地址,然后再通过这个地址进行访问。
2.防止恶意请求。
比如静态请求是*.html结尾的,动态请求是*.shtml,那么由此可以这么用,所有的*.shtml请求,必须 Referer 为我自己的网站。
Referer= http://www.google.com
空Referer是怎么回事?什么情况下会出现Referer?
首先,我们对空 Referer 的定义为, Referer 头部的内容为空,或者,一个 HTTP 请求中根本不包含 Referer 头部。
那么什么时候 HTTP 请求会不包含 Referer 字段呢?根据Referer的定义,它的作用是指示一个请求是从哪里链接过来,那么当一个请求并不是由链接触发产生的,那么自然也就不需要指定这个请求的链接来源。
比如,直接在浏览器的地址栏中输入一个资源的URL地址,那么这种请求是不会包含 Referer 字段的,因为这是一个“凭空产生”的 HTTP 请求,并不是从一个地方链接过去的。
那么在防盗链设置中,允许空Referer和不允许空Referer有什么区别?
允许 Referer 为空,意味着你允许比如浏览器直接访问,就是空。
X-Requested-With
X-Requested-With请求头用于在服务器端判断request来自Ajax请求还是传统请求。
如果 requestedWith 为 null,则为同步请求。如果 requestedWith 为 XMLHttpRequest 则为 Ajax 请求。 if (request.getHeader("x-requested-with") != null
&& request.getHeader("x-requested-with").equalsIgnoreCase("XMLHttpRequest")) {
out.print("该请求是 AJAX 异步HTTP请求。");
}else{
out.print("该请求是传统的 同步HTTP请求。");
}
如何在发送请求是去掉它?
$.ajax({
url: 'http://www.zhangruifeng.com',
beforeSend: function( xhr ) {
xhr.setRequestHeader('X-Requested-With', {toString: function(){ return ''; }});
},
success: function( data ) {
if (console && console.log){
console.log( 'Got data without the X-Requested-With header' );
}
}
});
前端优秀代码片段
前端开发 • zkbhj 发表了文章 • 0 个评论 • 3137 次浏览 • 2016-09-19 15:38
$("#head_car").hover(function(){
$(this).css("background", "#FBFEE9");
$(".head_car_text").css("color", "#ff6700");
$("#car_content").css({"width":"300px"}).animate({
height:"100px"
},400).finish();
},function(){
$(this).css("background", "#424242");
$(".head_car_text").css("color", "#b0b0b0");
$("#car_content").css({"width":"300px"}).animate({
height:"0px"
},400);
})
//导航栏控制显示
$(".menu_li").hover(function(){
$("#menu_content_bg").css("border","1px solid #D0D0D0");
$(this).css("color","#ff6700");
$("#"+$(this).attr("control")).show();
$("#menu_content_bg").height(230);
},function(){
$("#"+$(this).attr("control")).hide();
$(this).css("color"," #424242");
$("#menu_content_bg").height(0);
$("#menu_content_bg").css("border","0px solid #D0D0D0");
})
//搜索框失去和获取焦点border颜色改变
$("#find_input").focus(function(){
$("#find_wrap").css("border","1px solid #ff6700");
$("#find_but").css("border-left","1px solid #ff6700");
})
$("#find_input").blur(function(){
$("#find_wrap").css("border","1px solid #F0F0F0");
$("#find_but").css("border-left","1px solid #F0F0F0");
})
//搜索按钮的背景颜色改变
$("#find_but").hover(function(){
$(this).css({"background":"#ff6700",color:"#fff"});
},function(){
$(this).css({"background":"#fff",color:"#424242"});
})
//菜单栏的显示
$("#banner_menu_wrap").children().hover(function(){
$(this).css("background","#ff6700");
$(this).children(".banner_menu_content").css("border","1px solid #F0F0F0").show();
},function(){
$(this).css("background","none");
$(this).children(".banner_menu_content").css("border","0px solid #F0F0F0").hide();
}) 查看全部
//购物车控制显示
$("#head_car").hover(function(){
$(this).css("background", "#FBFEE9");
$(".head_car_text").css("color", "#ff6700");
$("#car_content").css({"width":"300px"}).animate({
height:"100px"
},400).finish();
},function(){
$(this).css("background", "#424242");
$(".head_car_text").css("color", "#b0b0b0");
$("#car_content").css({"width":"300px"}).animate({
height:"0px"
},400);
})
//导航栏控制显示
$(".menu_li").hover(function(){
$("#menu_content_bg").css("border","1px solid #D0D0D0");
$(this).css("color","#ff6700");
$("#"+$(this).attr("control")).show();
$("#menu_content_bg").height(230);
},function(){
$("#"+$(this).attr("control")).hide();
$(this).css("color"," #424242");
$("#menu_content_bg").height(0);
$("#menu_content_bg").css("border","0px solid #D0D0D0");
})
//搜索框失去和获取焦点border颜色改变
$("#find_input").focus(function(){
$("#find_wrap").css("border","1px solid #ff6700");
$("#find_but").css("border-left","1px solid #ff6700");
})
$("#find_input").blur(function(){
$("#find_wrap").css("border","1px solid #F0F0F0");
$("#find_but").css("border-left","1px solid #F0F0F0");
})
//搜索按钮的背景颜色改变
$("#find_but").hover(function(){
$(this).css({"background":"#ff6700",color:"#fff"});
},function(){
$(this).css({"background":"#fff",color:"#424242"});
})
//菜单栏的显示
$("#banner_menu_wrap").children().hover(function(){
$(this).css("background","#ff6700");
$(this).children(".banner_menu_content").css("border","1px solid #F0F0F0").show();
},function(){
$(this).css("background","none");
$(this).children(".banner_menu_content").css("border","0px solid #F0F0F0").hide();
})
jQuery报错Uncaught TypeError: a.indexOf is not a function 怎么处理?
回复前端开发 • zkbhj 回复了问题 • 1 人关注 • 1 个回复 • 5093 次浏览 • 2020-02-29 12:04
理解HTTP请求头中的参数:If-Modified-Since与Last-Modified
专业名词 • zkbhj 发表了文章 • 0 个评论 • 2408 次浏览 • 2020-01-17 10:25
Last-Modified 与If-Modified-Since 都是标准的HTTP请求头标签,用于记录页面的最后修改时间。
2.发送方向
Last-Modified 是由服务器发送给客户端的HTTP请求头标签
If-Modified-Since 则是由客户端发送给服务器的HTTP请求头标签
3.应用场景
(1)Last-Modified
在浏览器第一次请求某一个URL时,服务器端的返回状态会是200,内容是你请求的资源,同时有一个Last-Modified的属性标记此文件在服务期端最后被修改的时间,格式类似这样:
Last-Modified: Fri, 12 May 2006 18:53:33 GMT
后面跟的时间是服务器存储的文件修改时间
(2)If-Modified-Since
客户端第二次请求此URL时,根据 HTTP 协议的规定,浏览器会向服务器传送 If-Modified-Since 报头,询问该时间之后文件是否有被修改过:
If-Modified-Since: Fri, 12 May 2006 18:53:33 GMT
后面跟的时间是本地浏览器存储的文件修改时间
如果服务器端的资源没有变化,则时间一致,自动返回HTTP状态码304(Not Changed.)状态码,内容为空,客户端接到之后,就直接把本地缓存文件显示到浏览器中,这样就节省了传输数据量。
如果服务器端资源发生改变或者重启服务器时,时间不一致,就返回HTTP状态码200和新的文件内容,客户端接到之后,会丢弃旧文件,把新文件缓存起来,并显示到浏览器中。
以上操作可以保证不向客户端重复发出资源,也保证当服务器有变化时,客户端能够得到最新的资源。
————————————————
版权声明:本文为CSDN博主「上善若海」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lhl11242 ... 67764 查看全部
Last-Modified 与If-Modified-Since 都是标准的HTTP请求头标签,用于记录页面的最后修改时间。
2.发送方向
Last-Modified 是由服务器发送给客户端的HTTP请求头标签
If-Modified-Since 则是由客户端发送给服务器的HTTP请求头标签
3.应用场景
(1)Last-Modified
在浏览器第一次请求某一个URL时,服务器端的返回状态会是200,内容是你请求的资源,同时有一个Last-Modified的属性标记此文件在服务期端最后被修改的时间,格式类似这样:
Last-Modified: Fri, 12 May 2006 18:53:33 GMT
后面跟的时间是服务器存储的文件修改时间
(2)If-Modified-Since
客户端第二次请求此URL时,根据 HTTP 协议的规定,浏览器会向服务器传送 If-Modified-Since 报头,询问该时间之后文件是否有被修改过:
If-Modified-Since: Fri, 12 May 2006 18:53:33 GMT
后面跟的时间是本地浏览器存储的文件修改时间
如果服务器端的资源没有变化,则时间一致,自动返回HTTP状态码304(Not Changed.)状态码,内容为空,客户端接到之后,就直接把本地缓存文件显示到浏览器中,这样就节省了传输数据量。
如果服务器端资源发生改变或者重启服务器时,时间不一致,就返回HTTP状态码200和新的文件内容,客户端接到之后,会丢弃旧文件,把新文件缓存起来,并显示到浏览器中。
以上操作可以保证不向客户端重复发出资源,也保证当服务器有变化时,客户端能够得到最新的资源。
————————————————
版权声明:本文为CSDN博主「上善若海」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/lhl11242 ... 67764
JWT:完全前后端分离的项目如何做用户身份验证更安全?看这篇就够了!
前端开发 • zkbhj 发表了文章 • 0 个评论 • 4711 次浏览 • 2018-09-19 14:48
传统方式
前后端分离通过Restful API进行数据交互时,如何验证用户的登录信息及权限。在原来的项目中,使用的是最传统也是最简单的方式,前端登录,后端根据用户信息生成一个token,并保存这个 token 和对应的用户id到数据库或Session中,接着把 token 传给用户,存入浏览器 cookie,之后浏览器请求带上这个cookie,后端根据这个cookie值来查询用户,验证是否过期。
但这样做问题就很多,如果我们的页面出现了 XSS 漏洞,由于 cookie 可以被 JavaScript 读取,XSS 漏洞会导致用户 token 泄露,而作为后端识别用户的标识,cookie 的泄露意味着用户信息不再安全。尽管我们通过转义输出内容,使用 CDN 等可以尽量避免 XSS 注入,但谁也不能保证在大型的项目中不会出现这个问题。
在设置 cookie 的时候,其实你还可以设置 httpOnly 以及 secure 项。设置 httpOnly 后 cookie 将不能被 JS 读取,浏览器会自动的把它加在请求的 header 当中,设置 secure 的话,cookie 就只允许通过 HTTPS 传输。secure 选项可以过滤掉一些使用 HTTP 协议的 XSS 注入,但并不能完全阻止。
httpOnly 选项使得 JS 不能读取到 cookie,那么 XSS 注入的问题也基本不用担心了。但设置 httpOnly 就带来了另一个问题,就是很容易的被 XSRF,即跨站请求伪造。当你浏览器开着这个页面的时候,另一个页面可以很容易的跨站请求这个页面的内容。因为 cookie 默认被发了出去。
另外,如果将验证信息保存在数据库中,后端每次都需要根据token查出用户id,这就增加了数据库的查询和存储开销。若把验证信息保存在session中,有加大了服务器端的存储压力。那我们可不可以不要服务器去查询呢?如果我们生成token遵循一定的规律,比如我们使用对称加密算法来加密用户id形成token,那么服务端以后其实只要解密该token就可以知道用户的id是什么了。不过呢,我只是举个例子而已,要是真这么做,只要你的对称加密算法泄露了,其他人可以通过这种加密方式进行伪造token,那么所有用户信息都不再安全了。恩,那用非对称加密算法来做呢,其实现在有个规范就是这样做的,就是我们接下来要介绍的 JWT。
Json Web Token(JWT)
JWT 是一个开放标准(RFC 7519),它定义了一种用于简洁,自包含的用于通信双方之间以 JSON 对象的形式安全传递信息的方法。JWT 可以使用 HMAC 算法或者是 RSA 的公钥密钥对进行签名。它具备两个特点:
简洁(Compact)
可以通过URL, POST 参数或者在 HTTP header 发送,因为数据量小,传输速度快
自包含(Self-contained)
负载中包含了所有用户所需要的信息,避免了多次查询数据库
JWT 组成
Header 头部
头部包含了两部分,token 类型和采用的加密算法
{
"alg": "HS256",
"typ": "JWT"
}它会使用 Base64 编码组成 JWT 结构的第一部分,如果你使用Node.js,可以用Node.js的包base64url来得到这个字符串。
Base64是一种编码,也就是说,它是可以被翻译回原来的样子来的。它并不是一种加密过程。
Payload 负载
这部分就是我们存放信息的地方了,你可以把用户 ID 等信息放在这里,JWT 规范里面对这部分有进行了比较详细的介绍,常用的由 iss(签发者),exp(过期时间),sub(面向的用户),aud(接收方),iat(签发时间)。
{
"iss": "lion1ou JWT",
"iat": 1441593502,
"exp": 1441594722,
"aud": "www.example.com",
"sub": "lion1ou@163.com"
}同样的,它会使用 Base64 编码组成 JWT 结构的第二部分
Signature 签名
前面两部分都是使用 Base64 进行编码的,即前端可以解开知道里面的信息。Signature 需要使用编码后的 header 和 payload 以及我们提供的一个密钥,然后使用 header 中指定的签名算法(HS256)进行签名。签名的作用是保证 JWT 没有被篡改过。
三个部分通过.连接在一起就是我们的 JWT 了,它可能长这个样子,长度貌似和你的加密算法和私钥有关系。eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6IjU3ZmVmMTY0ZTU0YWY2NGZmYzUzZGJkNSIsInhzcmYiOiI0ZWE1YzUwOGE2NTY2ZTc2MjQwNTQzZjhmZWIwNmZkNDU3Nzc3YmUzOTU0OWM0MDE2NDM2YWZkYTY1ZDIzMzBlIiwiaWF0IjoxNDc2NDI3OTMzfQ.PA3QjeyZSUh7H0GfE0vJaKW4LjKJuC3dVLQiY4hii8s
其实到这一步可能就有人会想了,HTTP 请求总会带上 token,这样这个 token 传来传去占用不必要的带宽啊。如果你这么想了,那你可以去了解下 HTTP2,HTTP2 对头部进行了压缩,相信也解决了这个问题。
签名的目的
最后一步签名的过程,实际上是对头部以及负载内容进行签名,防止内容被窜改。如果有人对头部以及负载的内容解码之后进行修改,再进行编码,最后加上之前的签名组合形成新的JWT的话,那么服务器端会判断出新的头部和负载形成的签名和JWT附带上的签名是不一样的。如果要对新的头部和负载进行签名,在不知道服务器加密时用的密钥的话,得出来的签名也是不一样的。
信息暴露
在这里大家一定会问一个问题:Base64是一种编码,是可逆的,那么我的信息不就被暴露了吗?
是的。所以,在JWT中,不应该在负载里面加入任何敏感的数据。在上面的例子中,我们传输的是用户的User ID。这个值实际上不是什么敏感内容,一般情况下被知道也是安全的。但是像密码这样的内容就不能被放在JWT中了。如果将用户的密码放在了JWT中,那么怀有恶意的第三方通过Base64解码就能很快地知道你的密码了。
因此JWT适合用于向Web应用传递一些非敏感信息。JWT还经常用于设计用户认证和授权系统,甚至实现Web应用的单点登录。
JWT 使用
首先,前端通过Web表单将自己的用户名和密码发送到后端的接口。这一过程一般是一个HTTP POST请求。建议的方式是通过SSL加密的传输(https协议),从而避免敏感信息被嗅探。后端核对用户名和密码成功后,将用户的id等其他信息作为JWT Payload(负载),将其与头部分别进行Base64编码拼接后签名,形成一个JWT。形成的JWT就是一个形同lll.zzz.xxx的字符串。后端将JWT字符串作为登录成功的返回结果返回给前端。前端可以将返回的结果保存在localStorage或sessionStorage上,退出登录时前端删除保存的JWT即可。前端在每次请求时将JWT放入HTTP Header中的Authorization位。(解决XSS和XSRF问题)后端检查是否存在,如存在验证JWT的有效性。例如,检查签名是否正确;检查Token是否过期;检查Token的接收方是否是自己(可选)。验证通过后后端使用JWT中包含的用户信息进行其他逻辑操作,返回相应结果。
和Session方式存储id的差异
Session方式存储用户id的最大弊病在于Session是存储在服务器端的,所以需要占用大量服务器内存,对于较大型应用而言可能还要保存许多的状态。一般而言,大型应用还需要借助一些KV数据库和一系列缓存机制来实现Session的存储。
而JWT方式将用户状态分散到了客户端中,可以明显减轻服务端的内存压力。除了用户id之外,还可以存储其他的和用户相关的信息,例如该用户是否是管理员、用户所在的分组等。虽说JWT方式让服务器有一些计算压力(例如加密、编码和解码),但是这些压力相比磁盘存储而言可能就不算什么了。具体是否采用,需要在不同场景下用数据说话。
单点登录
Session方式来存储用户id,一开始用户的Session只会存储在一台服务器上。对于有多个子域名的站点,每个子域名至少会对应一台不同的服务器,例如:www.taobao.com,nv.taobao.com,nz.taobao.com,login.taobao.com。所以如果要实现在login.taobao.com登录后,在其他的子域名下依然可以取到Session,这要求我们在多台服务器上同步Session。使用JWT的方式则没有这个问题的存在,因为用户的状态已经被传送到了客户端。
总结
JWT的主要作用在于(一)可附带用户信息,后端直接通过JWT获取相关信息。(二)使用本地保存,通过HTTP Header中的Authorization位提交验证。但其实关于JWT存放到哪里一直有很多讨论,有人说存放到本地存储,有人说存 cookie。个人偏向于放在本地存储,如果你有什么意见和看法欢迎提出。
参考文档:
https://segmentfault.com/a/1190000005783306
https://ruiming.me/authentication-of-frontend-backend-separate-application/
总结和摘录自:
https://blog.csdn.net/kevin_lc ... 46723 查看全部
传统方式
前后端分离通过Restful API进行数据交互时,如何验证用户的登录信息及权限。在原来的项目中,使用的是最传统也是最简单的方式,前端登录,后端根据用户信息生成一个token,并保存这个 token 和对应的用户id到数据库或Session中,接着把 token 传给用户,存入浏览器 cookie,之后浏览器请求带上这个cookie,后端根据这个cookie值来查询用户,验证是否过期。
但这样做问题就很多,如果我们的页面出现了 XSS 漏洞,由于 cookie 可以被 JavaScript 读取,XSS 漏洞会导致用户 token 泄露,而作为后端识别用户的标识,cookie 的泄露意味着用户信息不再安全。尽管我们通过转义输出内容,使用 CDN 等可以尽量避免 XSS 注入,但谁也不能保证在大型的项目中不会出现这个问题。
在设置 cookie 的时候,其实你还可以设置 httpOnly 以及 secure 项。设置 httpOnly 后 cookie 将不能被 JS 读取,浏览器会自动的把它加在请求的 header 当中,设置 secure 的话,cookie 就只允许通过 HTTPS 传输。secure 选项可以过滤掉一些使用 HTTP 协议的 XSS 注入,但并不能完全阻止。
httpOnly 选项使得 JS 不能读取到 cookie,那么 XSS 注入的问题也基本不用担心了。但设置 httpOnly 就带来了另一个问题,就是很容易的被 XSRF,即跨站请求伪造。当你浏览器开着这个页面的时候,另一个页面可以很容易的跨站请求这个页面的内容。因为 cookie 默认被发了出去。
另外,如果将验证信息保存在数据库中,后端每次都需要根据token查出用户id,这就增加了数据库的查询和存储开销。若把验证信息保存在session中,有加大了服务器端的存储压力。那我们可不可以不要服务器去查询呢?如果我们生成token遵循一定的规律,比如我们使用对称加密算法来加密用户id形成token,那么服务端以后其实只要解密该token就可以知道用户的id是什么了。不过呢,我只是举个例子而已,要是真这么做,只要你的对称加密算法泄露了,其他人可以通过这种加密方式进行伪造token,那么所有用户信息都不再安全了。恩,那用非对称加密算法来做呢,其实现在有个规范就是这样做的,就是我们接下来要介绍的 JWT。
Json Web Token(JWT)
JWT 是一个开放标准(RFC 7519),它定义了一种用于简洁,自包含的用于通信双方之间以 JSON 对象的形式安全传递信息的方法。JWT 可以使用 HMAC 算法或者是 RSA 的公钥密钥对进行签名。它具备两个特点:
简洁(Compact)
可以通过URL, POST 参数或者在 HTTP header 发送,因为数据量小,传输速度快
自包含(Self-contained)
负载中包含了所有用户所需要的信息,避免了多次查询数据库
JWT 组成
Header 头部
头部包含了两部分,token 类型和采用的加密算法
{
"alg": "HS256",
"typ": "JWT"
}它会使用 Base64 编码组成 JWT 结构的第一部分,如果你使用Node.js,可以用Node.js的包base64url来得到这个字符串。
Base64是一种编码,也就是说,它是可以被翻译回原来的样子来的。它并不是一种加密过程。
Payload 负载
这部分就是我们存放信息的地方了,你可以把用户 ID 等信息放在这里,JWT 规范里面对这部分有进行了比较详细的介绍,常用的由 iss(签发者),exp(过期时间),sub(面向的用户),aud(接收方),iat(签发时间)。
{
"iss": "lion1ou JWT",
"iat": 1441593502,
"exp": 1441594722,
"aud": "www.example.com",
"sub": "lion1ou@163.com"
}同样的,它会使用 Base64 编码组成 JWT 结构的第二部分Signature 签名
前面两部分都是使用 Base64 进行编码的,即前端可以解开知道里面的信息。Signature 需要使用编码后的 header 和 payload 以及我们提供的一个密钥,然后使用 header 中指定的签名算法(HS256)进行签名。签名的作用是保证 JWT 没有被篡改过。
三个部分通过.连接在一起就是我们的 JWT 了,它可能长这个样子,长度貌似和你的加密算法和私钥有关系。
eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6IjU3ZmVmMTY0ZTU0YWY2NGZmYzUzZGJkNSIsInhzcmYiOiI0ZWE1YzUwOGE2NTY2ZTc2MjQwNTQzZjhmZWIwNmZkNDU3Nzc3YmUzOTU0OWM0MDE2NDM2YWZkYTY1ZDIzMzBlIiwiaWF0IjoxNDc2NDI3OTMzfQ.PA3QjeyZSUh7H0GfE0vJaKW4LjKJuC3dVLQiY4hii8s其实到这一步可能就有人会想了,HTTP 请求总会带上 token,这样这个 token 传来传去占用不必要的带宽啊。如果你这么想了,那你可以去了解下 HTTP2,HTTP2 对头部进行了压缩,相信也解决了这个问题。
签名的目的
最后一步签名的过程,实际上是对头部以及负载内容进行签名,防止内容被窜改。如果有人对头部以及负载的内容解码之后进行修改,再进行编码,最后加上之前的签名组合形成新的JWT的话,那么服务器端会判断出新的头部和负载形成的签名和JWT附带上的签名是不一样的。如果要对新的头部和负载进行签名,在不知道服务器加密时用的密钥的话,得出来的签名也是不一样的。
信息暴露
在这里大家一定会问一个问题:Base64是一种编码,是可逆的,那么我的信息不就被暴露了吗?
是的。所以,在JWT中,不应该在负载里面加入任何敏感的数据。在上面的例子中,我们传输的是用户的User ID。这个值实际上不是什么敏感内容,一般情况下被知道也是安全的。但是像密码这样的内容就不能被放在JWT中了。如果将用户的密码放在了JWT中,那么怀有恶意的第三方通过Base64解码就能很快地知道你的密码了。
因此JWT适合用于向Web应用传递一些非敏感信息。JWT还经常用于设计用户认证和授权系统,甚至实现Web应用的单点登录。
JWT 使用
- 首先,前端通过Web表单将自己的用户名和密码发送到后端的接口。这一过程一般是一个HTTP POST请求。建议的方式是通过SSL加密的传输(https协议),从而避免敏感信息被嗅探。
- 后端核对用户名和密码成功后,将用户的id等其他信息作为JWT Payload(负载),将其与头部分别进行Base64编码拼接后签名,形成一个JWT。形成的JWT就是一个形同lll.zzz.xxx的字符串。
- 后端将JWT字符串作为登录成功的返回结果返回给前端。前端可以将返回的结果保存在localStorage或sessionStorage上,退出登录时前端删除保存的JWT即可。
- 前端在每次请求时将JWT放入HTTP Header中的Authorization位。(解决XSS和XSRF问题)
- 后端检查是否存在,如存在验证JWT的有效性。例如,检查签名是否正确;检查Token是否过期;检查Token的接收方是否是自己(可选)。
- 验证通过后后端使用JWT中包含的用户信息进行其他逻辑操作,返回相应结果。
和Session方式存储id的差异
Session方式存储用户id的最大弊病在于Session是存储在服务器端的,所以需要占用大量服务器内存,对于较大型应用而言可能还要保存许多的状态。一般而言,大型应用还需要借助一些KV数据库和一系列缓存机制来实现Session的存储。
而JWT方式将用户状态分散到了客户端中,可以明显减轻服务端的内存压力。除了用户id之外,还可以存储其他的和用户相关的信息,例如该用户是否是管理员、用户所在的分组等。虽说JWT方式让服务器有一些计算压力(例如加密、编码和解码),但是这些压力相比磁盘存储而言可能就不算什么了。具体是否采用,需要在不同场景下用数据说话。
单点登录
Session方式来存储用户id,一开始用户的Session只会存储在一台服务器上。对于有多个子域名的站点,每个子域名至少会对应一台不同的服务器,例如:www.taobao.com,nv.taobao.com,nz.taobao.com,login.taobao.com。所以如果要实现在login.taobao.com登录后,在其他的子域名下依然可以取到Session,这要求我们在多台服务器上同步Session。使用JWT的方式则没有这个问题的存在,因为用户的状态已经被传送到了客户端。
总结
JWT的主要作用在于(一)可附带用户信息,后端直接通过JWT获取相关信息。(二)使用本地保存,通过HTTP Header中的Authorization位提交验证。但其实关于JWT存放到哪里一直有很多讨论,有人说存放到本地存储,有人说存 cookie。个人偏向于放在本地存储,如果你有什么意见和看法欢迎提出。
参考文档:
https://segmentfault.com/a/1190000005783306
https://ruiming.me/authentication-of-frontend-backend-separate-application/
总结和摘录自:
https://blog.csdn.net/kevin_lc ... 46723
来一起简单了解下单页面应用SPA
前端开发 • zkbhj 发表了文章 • 0 个评论 • 3068 次浏览 • 2018-05-25 17:39
单页 Web 应用 (single-page application 简称为 SPA) 是一种特殊的 Web 应用。它将所有的活动局限于一个Web页面中,仅在该Web页面初始化时加载相应的HTML、JavaScript 和 CSS。一旦页面加载完成了,SPA不会因为用户的操作而进行页面的重新加载或跳转。取而代之的是利用 JavaScript 动态的变换HTML的内容,从而实现UI与用户的交互。由于避免了页面的重新加载,SPA 可以提供较为流畅的用户体验。
二、优缺点
单页Web程序的出现是富客户端发展的必然结果,但是该技术也是有些局限性,所以采用之前需要了解清楚它的优缺点。
1、优点:
1).良好的交互体验
用户不需要重新刷新页面,获取数据也是通过Ajax异步获取,页面显示流畅。
2).良好的前后端工作分离模式
单页Web应用可以和RESTful规约一起使用,通过REST API提供接口数据,并使用Ajax异步获取,这样有助于分离客户端和服务器端工作。更进一步,可以在客户端也可以分解为静态页面和页面交互两个部分。
3).减轻服务器压力
服务器只用出数据就可以,不用管展示逻辑和页面合成,吞吐能力会提高几倍;
4).共用一套后端程序代码
不用修改后端程序代码就可以同时用于Web界面、手机、平板等多种客户端;
2、缺点:
1).SEO难度较高
由于所有的内容都在一个页面中动态替换显示,所以在SEO上其有着天然的弱势,所以如果你的站点对SEO很看重,且要用单页应用,那么就做些静态页面给搜索引擎用吧。
2).前进、后退管理
由于单页Web应用在一个页面中显示所有的内容,所以不能使用浏览器的前进后退功能,所有的页面切换需要自己建立堆栈管理,当然此问题也有解决方案,比如利用URI中的散列+iframe实现。
3).初次加载耗时多
为实现单页Web应用功能及显示效果,需要在加载页面的时候将JavaScript、CSS统一加载,部分页面可以在需要的时候加载。所以必须对JavaScript及CSS代码进行合并压缩处理,如果使用第三方库,建议使用一些大公司的CDN,因此带宽的消耗是必然的
二、单页面应用实现的原理
1、基本实现原理:利用ajax请求替代了a标签的默认跳转,然后利用html5中的API修改了url,这项技术并没有特别标准的学名,大家都称呼为Pjax,意为PushState + Ajax。这并不完全准确,因为还有Hash + Ajax等方法
2、Pjax是一个优秀的解决方案,你有足够多的理由来使用它:
可以在页面切换间平滑过渡,增加Loading动画。可以在各个页面间传递数据,不依赖URL。可以选择性的保留状态,如音乐网站,切换页面时不会停止播放歌曲。所有的标签都可以用来跳转,不仅仅是a标签。避免了公共JS的反复执行,如无需在各个页面打开时都判断是否登录过等等。减少了请求体积,节省流量,加快页面响应速度。平滑降级到低版本浏览器上,对SEO也不会有影响。
3、深剖原理
拦截a标签的默认跳转动作。
2. 使用Ajax请求新页面。
3. 将返回的Html替换到页面中。
4. 使用HTML5的History API或者Url的Hash修改Url。
4、HTML5 History APIhistory.pushState(state, title, url)
pushState方法会将当前的url添加到历史记录中,然后修改当前url为新url。请注意,这个方法只会修改地址栏的Url显示,但并不会发出任何请求。我们正是基于此特性来实现Pjax。它有3个参数:
state: 可以放任意你想放的数据,它将附加到新url上,作为该页面信息的一个补充。title: 顾名思义,就是document.title。不过这个参数目前并无作用,浏览器目前会选择忽略它。url: 新url,也就是你要显示在地址栏上的url。
history.replaceState(state, title, url)
replaceState方法与pushState大同小异,区别只在于pushState会将当前url添加到历史记录,之后再修改url,而replaceState只是修改url,不添加历史记录。
window.onpopstate 事件
一般来说,每当url变动时,popstate事件都会被触发。但若是调用pushState来修改url,该事件则不会触发,因此,我们可以把它用作浏览器的前进后退事件。该事件有一个参数,就是上文pushState方法的第一个参数state。 查看全部
单页 Web 应用 (single-page application 简称为 SPA) 是一种特殊的 Web 应用。它将所有的活动局限于一个Web页面中,仅在该Web页面初始化时加载相应的HTML、JavaScript 和 CSS。一旦页面加载完成了,SPA不会因为用户的操作而进行页面的重新加载或跳转。取而代之的是利用 JavaScript 动态的变换HTML的内容,从而实现UI与用户的交互。由于避免了页面的重新加载,SPA 可以提供较为流畅的用户体验。
二、优缺点
单页Web程序的出现是富客户端发展的必然结果,但是该技术也是有些局限性,所以采用之前需要了解清楚它的优缺点。
1、优点:
1).良好的交互体验
用户不需要重新刷新页面,获取数据也是通过Ajax异步获取,页面显示流畅。
2).良好的前后端工作分离模式
单页Web应用可以和RESTful规约一起使用,通过REST API提供接口数据,并使用Ajax异步获取,这样有助于分离客户端和服务器端工作。更进一步,可以在客户端也可以分解为静态页面和页面交互两个部分。
3).减轻服务器压力
服务器只用出数据就可以,不用管展示逻辑和页面合成,吞吐能力会提高几倍;
4).共用一套后端程序代码
不用修改后端程序代码就可以同时用于Web界面、手机、平板等多种客户端;
2、缺点:
1).SEO难度较高
由于所有的内容都在一个页面中动态替换显示,所以在SEO上其有着天然的弱势,所以如果你的站点对SEO很看重,且要用单页应用,那么就做些静态页面给搜索引擎用吧。
2).前进、后退管理
由于单页Web应用在一个页面中显示所有的内容,所以不能使用浏览器的前进后退功能,所有的页面切换需要自己建立堆栈管理,当然此问题也有解决方案,比如利用URI中的散列+iframe实现。
3).初次加载耗时多
为实现单页Web应用功能及显示效果,需要在加载页面的时候将JavaScript、CSS统一加载,部分页面可以在需要的时候加载。所以必须对JavaScript及CSS代码进行合并压缩处理,如果使用第三方库,建议使用一些大公司的CDN,因此带宽的消耗是必然的
二、单页面应用实现的原理
1、基本实现原理:利用ajax请求替代了a标签的默认跳转,然后利用html5中的API修改了url,这项技术并没有特别标准的学名,大家都称呼为Pjax,意为PushState + Ajax。这并不完全准确,因为还有Hash + Ajax等方法
2、Pjax是一个优秀的解决方案,你有足够多的理由来使用它:
- 可以在页面切换间平滑过渡,增加Loading动画。
- 可以在各个页面间传递数据,不依赖URL。
- 可以选择性的保留状态,如音乐网站,切换页面时不会停止播放歌曲。
- 所有的标签都可以用来跳转,不仅仅是a标签。
- 避免了公共JS的反复执行,如无需在各个页面打开时都判断是否登录过等等。
- 减少了请求体积,节省流量,加快页面响应速度。
- 平滑降级到低版本浏览器上,对SEO也不会有影响。
3、深剖原理
拦截a标签的默认跳转动作。
2. 使用Ajax请求新页面。
3. 将返回的Html替换到页面中。
4. 使用HTML5的History API或者Url的Hash修改Url。
4、HTML5 History API
history.pushState(state, title, url)
pushState方法会将当前的url添加到历史记录中,然后修改当前url为新url。请注意,这个方法只会修改地址栏的Url显示,但并不会发出任何请求。我们正是基于此特性来实现Pjax。它有3个参数:
- state: 可以放任意你想放的数据,它将附加到新url上,作为该页面信息的一个补充。
- title: 顾名思义,就是document.title。不过这个参数目前并无作用,浏览器目前会选择忽略它。
- url: 新url,也就是你要显示在地址栏上的url。
history.replaceState(state, title, url)
replaceState方法与pushState大同小异,区别只在于pushState会将当前url添加到历史记录,之后再修改url,而replaceState只是修改url,不添加历史记录。
window.onpopstate 事件
一般来说,每当url变动时,popstate事件都会被触发。但若是调用pushState来修改url,该事件则不会触发,因此,我们可以把它用作浏览器的前进后退事件。该事件有一个参数,就是上文pushState方法的第一个参数state。
饿了么的PWA升级实践
前端开发 • zkbhj 发表了文章 • 0 个评论 • 3018 次浏览 • 2018-02-03 14:00
多页应用、 Vue.js、 PWA?
对于构建一个希望达到原生应用级别体验的PWA,目前社区里的主流做法都是采用SPA,即单页面应用模型(Single-page App)来组织整个Web应用,业内最有名的几个PWA案例Twitter Lite、 Flipkart Lite、Housing Go 与 Polymer Shop无一例外。
然而饿了么,与很多国内的电商网站一样,青睐多页面应用模型(MPA, Multi-page App)所能带来的一些好处,也因此在一年多前就将移动站从基于AngularJS的单页应用重构为目前的多页应用模型。团队最看重的优点莫过于页面与页面之间的隔离与解耦,这使得我们可以将每个页面当做一个独立的“微服务”来看待,这些服务可以被独立迭代,独立提供给各种第三方的入口嵌入,甚至被不同的团队独立维护。而整个网站则只是各种服务的集合而非一个巨大的整体。
与此同时,我们仍然依赖 Vue.js作为JavaScript框架。 Vue.js除了是React、 AngularJS这种“重型武器”的竞争对手外,其轻量与高性能的优点使得它同样可以作为传统多页应用开发中流行的“jQuery/Zepto/Kissy+模板引擎”技术栈的完美替代。 Vue.js提供的组件系统、声明式与响应式编程更是提升了代码组织、共享、数据流控制、渲染等各个环节的开发效率。 Vue 还是一个渐进式框架,如果网站的复杂度继续提升,我们可以按需、增量地引入Vuex或Vue-Router这些模块。万一哪天又要改回单页呢?(谁知道呢……)
2017年, PWA已经成为Web应用新的风潮。我们决定试试,以我们现有的“Vue.js+多页”架构,能在升级PWA的道路上走多远,达到怎样的效果。
实现“PRPL”模式
“PRPL”(读作“purple”)是Google工程师提出的一种Web应用架构模式,它旨在利用现代Web平台的新技术以大幅优化移动Web的性能与体验,对如何组织与设计高性能的PWA系统提供了一种高层次的抽象。我们并不准备从头重构我们的Web应用,不过我们可以把实现“PRPL”模式作为我们的迁移目标。“PRPL”实际上是“Push/Preload、 Render、 Precache、 Lazy-Load”的缩写,我们接下来会展开介绍它们的具体含义。
Push/Preload,推送/预加载初始URL路由所需的关键资源
无论是HTTP2 Server Push还是,其关键都在于,我们希望提前请求一些隐藏在应用依赖关系(Dependency Graph)较深处的资源,以节省HTTP往返、浏览器解析文档,或脚本执行的时间。比如说,对于一个基于路由进行code splitting的SPA,如果我们可以在Webpack清单、路由等入口代码(entry chunks)被下载与运行之前就把初始URL,即用户访问的入口URL路由所依赖的代码用Server Push推送或进行提前加载。那么当这些资源被真正请求时,它们可能已经下载好并存在缓存中了,这样就加快了初始路由所有依赖的就绪。
在多页应用中,每一个路由本来就只会请求这个路由所需要的资源,并且通常依赖也都比较扁平。饿了么移动站的大部分脚本依赖都是普通的 <script> 元素,因此他们可以在文档解析早期就被浏览器的preloader扫描出来并且开始请求,其效果其实与显式的是一致的,见图1所示。
图1 有无<link rel=“preload”>的效果对比
我们还将所有关键的静态资源都伺服在同一域名下(不再做域名散列),以更好地利用HTTP2带来的多路复用(Multiplexing)。同时,我们也在进行着对API进行Server Push的实验。
Render,渲染初始路由,尽快让应用可被交互
既然所有初始路由的依赖都已经就绪,我们就可以尽快开始初始路由的渲染,这有助于提升应用诸如首次渲染时间、可交互时间等指标。多页应用并不使用基于JavaScript的路由,而是传统的HTML跳转机制,所以对于这一部分,多页应用其实不用额外做什么。
Precache,用Service Worker预缓存剩下的路由
这一部分就需要Service Worker的参与了。Service Worker是一个位于浏览器与网络之间的客户端代理,它已可拦截、处理、响应流经的HTTP请求,使得开发者得以从缓存中向Web应用提供资源而闻名。不过, Service Worker其实也可以主动发起 HTTP 请求,在“后台”预请求与预缓存我们未来所需要的资源,见图2所示。
图2 Service Worker预缓存未来所需要的资源
我们已经使用Webpack在构建过程中进行.vue编译、文件名哈希等工作,于是我们编写了一个Webpack插件来帮助收集需要缓存的依赖到一个“预缓存清单”中,并使用这个清单在每次构建时生成新的Service Worker文件。在新的Service Worker被激活时,清单里的资源就会被请求与缓存,这其实与SW-Precache 这个库的运行机制非常接近。
实际上,我们只对标记为“关键路由”的路由进行依赖收集。你可以将这些“关键路由”的依赖理解为我们整个应用的“App Shell” 或者说“安装包”。一旦它们都被缓存,或者说成功安装,无论用户是在线离线,我们的Web应用都可以从缓存中直接启动。对于那些并不那么重要的路由,我们则采取在运行时增量缓存的方式。我们使用的SW-Toolbox提供了LRU替换策略与TTL失效机制,可以保证我们的应用不会超过浏览器的缓存配额。
Lazy-Load,按需懒加载、懒实例化剩下的路由
懒加载与懒实例化剩下的路由对于SPA是一件相对麻烦点儿的事情,你需要实现基于路由的code splitting与异步加载。幸运的是,这又是一件不需要多页应用担心的事情,多页应用中的各个路由天生就是分离的。
值得说明的是,无论单页还是多页应用,如果在上一步中,我们已经将这些路由的资源都预先下载与缓存好了,那么懒加载就几乎是瞬时完成的了,这时候我们就只需要付出实例化的代价。
至此,我们对PRPL的四部分含义做了详细说明。有趣的是,我们发现多页应用在实现PRPL这件事甚至比单页还要容易一些。那么结果如何呢?
根据Google推出的Web性能分析工具Lighthouse(v1.6),在模拟的3G网络下,用户的初次访问(无任何缓存)大约在2秒左右达到“可交互”,可以说非常不错,见图3所示。而对于再次访问,由于所有资源都直接来自于Service Worker缓存,页面可以在1秒左右就达到可交互的状态了。
图3 Lighthouse跑分结果
但是,故事并不是这么简单得就结束了。在实际体验中我们发现,应用在页与页的切换时,仍然存在着非常明显的白屏空隙,见图4所示。由于PWA是全屏运行,白屏对用户体验所带来的负面影响甚至比以往在浏览器内更大。我们不是已经用Service Worker缓存了所有资源了吗,怎么还会这样呢?
图4 从首页点击到发现页,跳转过程中的白屏
多页应用的陷阱:重启开销
与SPA不同,在多页应用中,路由的切换是原生的浏览器文档跳转(Navigating across documents),这意味着之前的页面会被完全丢弃而浏览器需要为下一个路由的页面重新执行所有的启动步骤:重新下载资源、重新解析HTML、重新运行JavaScript、重新解码图片、重新布局页面、重新绘制……即使其中的很多步骤本是可以在多个路由之间复用的。这些工作无疑将产生巨大的计算开销,也因此需要付出相当多的时间成本。
图5中为我们的入口页(同时也是最重要的页面)在两倍CPU节流模拟下的Profile数据。即使我们可以将“可交互时间”控制在 1 秒左右,我们的用户仍然会觉得这对于“仅仅切换个标签”来说实在是太慢了。
图5 入口页在两倍CPU节流模拟下的Profile数据
巨大的JavaScript重启开销
根据Profile,我们发现在首次渲染(First Paint)发生之前,大量的时间(900ms)都消耗在了JavaScript的运行上(Evaluate Script)。几乎所有脚本都是阻塞的(Parser-blocking),不过因为所有的UI都是由JavaScript/Vue.js驱动的,倒也不会有性能影响。这900ms中,约一半是消耗在Vue.js运行时、组件、库等依赖的运行上,而另一半则花在了业务组件实例化时Vue.js的启动与渲染上。从软件工程角度来说,我们需要这些抽象,所以这里并不是想责怪JavaScript或是Vue.js所带来的开销。
但是,在SPA中, JavaScript的启动成本是均摊到整个生命周期的:每个脚本都只需要被解析与编译一次,诸如生成Virtual DOM等较重的任务可以只执行一次,像Vue.js的ViewModel或是Virtual DOM这样的大对象也可以被留在内存里复用。可惜在多页应用里就不是这样了,我们每次切换页面都为JavaScript付出了巨大的重启代价。
浏览器的缓存啊,能不能帮帮忙?
能,也不能。
V8提供了代码缓存(code caching),可以将编译后的机器码在本地拷贝一份,这样我们就可以在下次请求同一个脚本时一次省略掉请求、解析、编译的所有工作。而且,对于缓存在Service Worker配套的Cache Storage中的脚本,会在第一次执行后就触发V8的代码缓存,这对于我们的多页切换能提供不少帮助。
另外一个你或许听过的浏览器缓存叫做“进退缓存”, Back-Forward Cache,简称bfcache。浏览器厂商对其的命名各异, Opera称之为Fast History Navigation, Webkit称其为Page Cache。但是思路都一样,就是我们可以让浏览器在跳转时把前一页留存在内存中,保留JavaScript与DOM的状态,而不是全都销毁掉。你可以随便找个传统的多页网站在iOS Safari上试试,无论是通过浏览器的前进后退按钮、手势,还是通过超链接(会有一些不同),基本都可以看到瞬间加载的效果。
Bfcache其实非常适合多页应用。但不幸的是,Chrome由于内存开销与其多进程架构等原因目前并不支持。 Chrome现阶段仅仅只是用了传统的HTTP磁盘缓存,来稍稍简化了一下加载过程而已。对于Chromium内核霸占的Android生态来说,我们没法指望了。
为“感知体验”奋斗
尽管多页应用面临着现实中的不少性能问题,我们并不想这么快就妥协。一方面,我们尝试尽可能减少在页面达到可交互时间前的代码执行量,比如减少/推迟一些依赖脚本的执行,还有减少初次渲染的DOM节点数以节省Virtual DOM的初始化开销。另一方面,我们也意识到应用在感知体验上还有更多的优化空间。
Chrome产品经理Owen写过一篇Reactive Web Design: The secret to building web apps that feel amazing,谈到两种改进感知体验的手段:一是使用骨架屏(Skeleton Screen)来实现瞬间加载;二是预先定义好元素的尺寸来保证加载的稳定。跟我们的做法可以说不谋而合。
为了消除白屏时间,我们同样引入了尺寸稳定的骨架屏来帮助我们实现瞬间的加载与占位。即使是在硬件很弱的设备上,我们也可以在点击切换标签后立刻渲染出目标路由的骨架屏,以保证UI是稳定、连续、有响应的。我录了两个视频放在Youtube上,不过如果你是国内读者,你可以直接访问饿了么移动网站来体验实地的效果。最终效果如图6所示。
为“感知体验”奋斗
尽管多页应用面临着现实中的不少性能问题,我们并不想这么快就妥协。一方面,我们尝试尽可能减少在页面达到可交互时间前的代码执行量,比如减少/推迟一些依赖脚本的执行,还有减少初次渲染的DOM节点数以节省Virtual DOM的初始化开销。另一方面,我们也意识到应用在感知体验上还有更多的优化空间。
Chrome产品经理Owen写过一篇Reactive Web Design: The secret to building web apps that feel amazing,谈到两种改进感知体验的手段:一是使用骨架屏(Skeleton Screen)来实现瞬间加载;二是预先定义好元素的尺寸来保证加载的稳定。跟我们的做法可以说不谋而合。
为了消除白屏时间,我们同样引入了尺寸稳定的骨架屏来帮助我们实现瞬间的加载与占位。即使是在硬件很弱的设备上,我们也可以在点击切换标签后立刻渲染出目标路由的骨架屏,以保证UI是稳定、连续、有响应的。我录了两个视频放在Youtube上,不过如果你是国内读者,你可以直接访问饿了么移动网站来体验实地的效果。最终效果如图6所示。
图6 在添加骨架屏后,从发现页点回首页的效果
这效果本该很轻松的就能实现,不过实际上我们还费了点功夫。
在构建时使用 Vue 预渲染骨架屏
你可能已经想到了,为了让骨架屏可以被Service Worker缓存,瞬间加载并独立于JavaScript渲染,我们需要把组成骨架屏的HTML标签、 CSS样式与图片资源一并内联至各个路由的静态*.html文件中。
不过,我们并不准备手动编写这些骨架屏。你想啊,如果每次真实组件有迭代(每一个路由对我们来说都是一个Vue.js组件),我们都需要手动去同步每一个变化到骨架屏的话,那实在是太繁琐且难以维护了。好在,骨架屏不过是当数据还未加载进来前,页面的一个空白版本而已。如果我们能将骨架屏实现为真实组件的一个特殊状态——“空状态”的话,从理论上就可以从真实组件中直接渲染出骨架屏来。
而Vue.js的多才多艺就在这时体现出来了,我们真的可以用Vue.js 的服务端渲染模块来实现这个想法,不过不是用在真正的服务器上,而是在构建时用它把组件的空状态预先渲染成字符串并注入到HTML模板中。你需要调整Vue.js组件代码使得它可以在Node上执行,有些页面对DOM/BOM的依赖一时无法轻易去除得,我们目前只好额外编写一个*.shell.vue来暂时绕过这个问题。
关于浏览器的绘制(Painting)
HTML文件中有标签并不意味着这些标签就能立刻被绘制到屏幕上,你必须保证页面的关键渲染路径是为此优化的。很多开发者相信将Script标签放在body的底部就足以保证内容能在脚本执行之前被绘制,这对于能渲染不完整DOM树的浏览器(比如桌面浏览器常见的流式渲染)来说可能是成立的。但移动端的浏览器很可能因为考虑到较慢的硬件、电量消耗等因素并不这么做。不仅如此,即使你曾被告知设为async或defer的脚本就不会阻塞HTML解析了,但这可不意味着浏览 器就一定会在执行它们之前进行渲染。
首先我想澄清的是,根据 HTML 规范 Scripting 章节, async脚本是在其请求完成后立刻运行的,因此它本来就可能阻塞到解析。只有defer(且非内联)与最新的type=module被指定为“一定不会阻塞解析”(不过defer目前也有点小问题……我们稍后会再提到),见图7所示。
图7 具有不同属性的Script脚本对HTML解析的阻塞情况
而更重要的是,一个不阻塞HTML解析的脚本仍然可能阻塞到绘制。我做了一个简化的“最小多页PWA”(Minimal Multi-page PWA,或MMPWA)来测试这个问题:我们在一个async(且确实不阻塞HTML解析)脚本中,生成并渲染1000个列表项,然后测试骨架屏能否在脚本执行之前渲染出来。图8是通过USB Debugging在我的Nexus 5真机上录制的Profile。
图8 通过USB Debugging在Nexus 5真机上录制的Profile
是的,出乎意料吗?首次渲染确实被阻塞到脚本执行结束后才发生。究其原因,如果我们在浏览器还未完成上一次绘制工作之前就过快得进行了DOM操作,我们亲爱的浏览器就只好抛弃所有它已经完成的像素,且一直要等待到DOM操作引起的所有工作结束之后才能重新进行下一次渲染。而这种情况更容易在拥有较慢CPU/GPU的移动设备上出现。
黑魔法:利用setTimeout()让绘制提前
不难发现,骨架屏的绘制与脚本执行实际是一个竞态。大概是Vue.js太快了,我们的骨架屏还是有非常大的概率绘制不出来。于是我们想着如何能让脚本执行慢点,或者说,“懒”点。于是我们想到了一个经典的Hack: setTimeout(callback, 0)。我们试着把MMPWA中的DOM操作(渲染1000个列表)放进setTimeout(callback, 0)里……
当当!首次渲染瞬间就被提前了,见图9所示。如果你熟悉浏览器的事件循环模型(Event Loop)的话,这招Hack其实是通过setTimeout的回调把DOM操作放到了事件循环的任务队列中以避免它在当前循环执行,这样浏览器就得以在主线程空闲时喘息一下(更新一下渲染)了。如果你想亲手试试 MMPWA的话,你可以访问github.com/Huxpro/mmpwa 或huangxuan.me/mmpwa/ ,查看代码与Demo。我把UI设计成了A/B Test的形式并改为渲染5000个列表项来让效果更夸张一些。
图9 利用Hack技术,提前完成骨架屏的绘制
回到饿了么PWA上,我们同样试着把new Vue()放到了setTimeout中。果然,黑魔法再次显灵,骨架屏在每次跳转后都能立刻被渲染。这时的Profile看起来是这样的,见图10所示。
图10 为感知体验进行各种优化后的最终Profile
现在,我们在400ms时触发首次渲染(骨架屏),在600ms时完成真实UI的渲染并达到页面的可交互。你可以详细对比下图9和图10所示的优化前后Profile的区别。
被我“defer”的有关defer的Bug
不知道你发现没有,在图10的Profile中,我们仍然有不少脚本是阻塞了HTML解析的。好吧,让我解释一下,由于历史原因,我们确实保留了一部分的阻塞脚本,比如侵入性很强的lib-flexible,我们没法轻易去除它。不过, Profile里的大部分阻塞脚本实际上都设置了defer,我们本以为他们应该在HTML解析完成之后才被执行,结果被Profile打了一脸。
我和Jake Archibald 聊了一下,果然这是Chrome的Bug: defer的脚本被完全缓存时,并没有遵守规范等待解析结束,反而阻塞了解析与渲染。Jake已经提交在crbug上了,一起给它投票吧。
最后,图11是优化后的Lighthouse跑分结果,同样可以看到明显的性能提升。需要说明的是,能影响Lighthouse跑分的因素有很多,所以我建议你以控制变量(跑分用的设备、跑分时的网络环境等)的方式来进行对照实验。
图11 优化后的Lighthouse跑分结果
最后为大家展示下应用的架构示意图,见图12所示。
图12 应用架构示意图
一些感想
多页应用仍然有很长的路要走
Web是一个极其多样化的平台。从静态的博客,到电商网站,再到桌面级的生产力软件,它们全都是Web这个大家庭的第一公民。而我们组织Web应用的方式,也同样只会更多而不会更少:多页、单页、 Universal JavaScript应用、 WebGL,以及可以预见的Web Assembly。不同的技术之间没有贵贱,但是适用场景的差距确是客观存在的。
Jake 曾在 Chrome Dev Summit 2016 上说过“PWA!== SPA”。可是尽管我们已经用上了一系列最新的技术(PRPL、 Service Worker、 App Shell……),我们仍然因为多页应用模型本身的缺陷有着难以逾越的一些障碍。多页应用在未来可能会有“bfcache API”、 Navigation Transition等新的规范以缩小跟SPA的距离,不过我们也必须承认,时至今日,多页应用的局限性也是非常明显的。
而PWA终将带领Web应用进入新的时代
即使我们的多页应用在升级PWA的路上不如单页应用来得那么闪亮,但是PWA背后的想法与技术却实实在在地帮助我们在Web平台上提供了更好的用户体验。
PWA作为下一代 Web 应用模型,其尝试解决的是Web平台本身的根本性问题:对网络与浏览器UI的硬依赖。因此,任何Web应用都可以从中获益,这与你是多页还是单页、面向桌面还是移动端、是用React还是Vue.js无关。或许,它还终将改变用户对移动Web的期待。现如今,谁还觉得桌面端的Web只是个看文档的地方呢?
还是那句老话,让我们的用户,也像我们这般热爱Web吧。
最后,感谢饿了么的王亦斯、任光辉、题叶,Google 的 Michael Yeung、 DevRel 团队, UC浏览器团队,腾讯X5浏览器团队在这次项目中的合作。感谢尤雨溪、陈蒙迪和Jake Archibald 在写作过程中给予我的帮助。
原文阅读:https://zhuanlan.zhihu.com/p/27836133 查看全部
多页应用、 Vue.js、 PWA?
对于构建一个希望达到原生应用级别体验的PWA,目前社区里的主流做法都是采用SPA,即单页面应用模型(Single-page App)来组织整个Web应用,业内最有名的几个PWA案例Twitter Lite、 Flipkart Lite、Housing Go 与 Polymer Shop无一例外。
然而饿了么,与很多国内的电商网站一样,青睐多页面应用模型(MPA, Multi-page App)所能带来的一些好处,也因此在一年多前就将移动站从基于AngularJS的单页应用重构为目前的多页应用模型。团队最看重的优点莫过于页面与页面之间的隔离与解耦,这使得我们可以将每个页面当做一个独立的“微服务”来看待,这些服务可以被独立迭代,独立提供给各种第三方的入口嵌入,甚至被不同的团队独立维护。而整个网站则只是各种服务的集合而非一个巨大的整体。
与此同时,我们仍然依赖 Vue.js作为JavaScript框架。 Vue.js除了是React、 AngularJS这种“重型武器”的竞争对手外,其轻量与高性能的优点使得它同样可以作为传统多页应用开发中流行的“jQuery/Zepto/Kissy+模板引擎”技术栈的完美替代。 Vue.js提供的组件系统、声明式与响应式编程更是提升了代码组织、共享、数据流控制、渲染等各个环节的开发效率。 Vue 还是一个渐进式框架,如果网站的复杂度继续提升,我们可以按需、增量地引入Vuex或Vue-Router这些模块。万一哪天又要改回单页呢?(谁知道呢……)
2017年, PWA已经成为Web应用新的风潮。我们决定试试,以我们现有的“Vue.js+多页”架构,能在升级PWA的道路上走多远,达到怎样的效果。
实现“PRPL”模式
“PRPL”(读作“purple”)是Google工程师提出的一种Web应用架构模式,它旨在利用现代Web平台的新技术以大幅优化移动Web的性能与体验,对如何组织与设计高性能的PWA系统提供了一种高层次的抽象。我们并不准备从头重构我们的Web应用,不过我们可以把实现“PRPL”模式作为我们的迁移目标。“PRPL”实际上是“Push/Preload、 Render、 Precache、 Lazy-Load”的缩写,我们接下来会展开介绍它们的具体含义。
Push/Preload,推送/预加载初始URL路由所需的关键资源
无论是HTTP2 Server Push还是,其关键都在于,我们希望提前请求一些隐藏在应用依赖关系(Dependency Graph)较深处的资源,以节省HTTP往返、浏览器解析文档,或脚本执行的时间。比如说,对于一个基于路由进行code splitting的SPA,如果我们可以在Webpack清单、路由等入口代码(entry chunks)被下载与运行之前就把初始URL,即用户访问的入口URL路由所依赖的代码用Server Push推送或进行提前加载。那么当这些资源被真正请求时,它们可能已经下载好并存在缓存中了,这样就加快了初始路由所有依赖的就绪。
在多页应用中,每一个路由本来就只会请求这个路由所需要的资源,并且通常依赖也都比较扁平。饿了么移动站的大部分脚本依赖都是普通的 <script> 元素,因此他们可以在文档解析早期就被浏览器的preloader扫描出来并且开始请求,其效果其实与显式的是一致的,见图1所示。
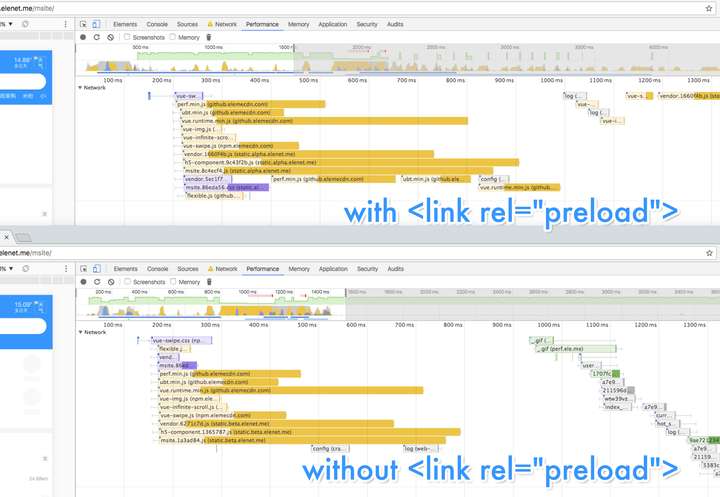
图1 有无<link rel=“preload”>的效果对比
我们还将所有关键的静态资源都伺服在同一域名下(不再做域名散列),以更好地利用HTTP2带来的多路复用(Multiplexing)。同时,我们也在进行着对API进行Server Push的实验。
Render,渲染初始路由,尽快让应用可被交互
既然所有初始路由的依赖都已经就绪,我们就可以尽快开始初始路由的渲染,这有助于提升应用诸如首次渲染时间、可交互时间等指标。多页应用并不使用基于JavaScript的路由,而是传统的HTML跳转机制,所以对于这一部分,多页应用其实不用额外做什么。
Precache,用Service Worker预缓存剩下的路由
这一部分就需要Service Worker的参与了。Service Worker是一个位于浏览器与网络之间的客户端代理,它已可拦截、处理、响应流经的HTTP请求,使得开发者得以从缓存中向Web应用提供资源而闻名。不过, Service Worker其实也可以主动发起 HTTP 请求,在“后台”预请求与预缓存我们未来所需要的资源,见图2所示。
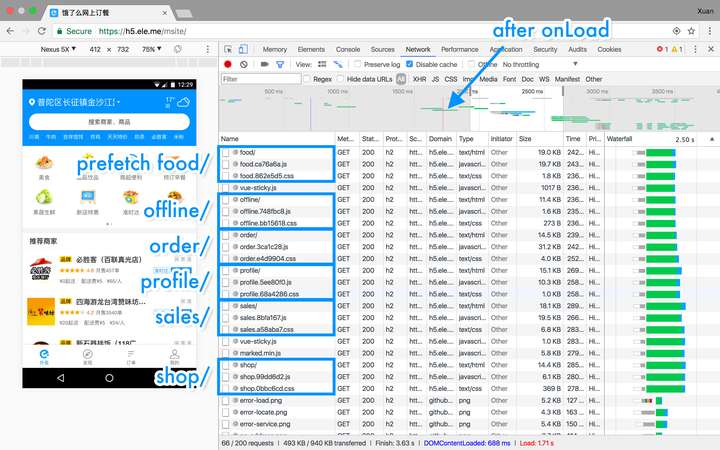
图2 Service Worker预缓存未来所需要的资源
我们已经使用Webpack在构建过程中进行.vue编译、文件名哈希等工作,于是我们编写了一个Webpack插件来帮助收集需要缓存的依赖到一个“预缓存清单”中,并使用这个清单在每次构建时生成新的Service Worker文件。在新的Service Worker被激活时,清单里的资源就会被请求与缓存,这其实与SW-Precache 这个库的运行机制非常接近。
实际上,我们只对标记为“关键路由”的路由进行依赖收集。你可以将这些“关键路由”的依赖理解为我们整个应用的“App Shell” 或者说“安装包”。一旦它们都被缓存,或者说成功安装,无论用户是在线离线,我们的Web应用都可以从缓存中直接启动。对于那些并不那么重要的路由,我们则采取在运行时增量缓存的方式。我们使用的SW-Toolbox提供了LRU替换策略与TTL失效机制,可以保证我们的应用不会超过浏览器的缓存配额。
Lazy-Load,按需懒加载、懒实例化剩下的路由
懒加载与懒实例化剩下的路由对于SPA是一件相对麻烦点儿的事情,你需要实现基于路由的code splitting与异步加载。幸运的是,这又是一件不需要多页应用担心的事情,多页应用中的各个路由天生就是分离的。
值得说明的是,无论单页还是多页应用,如果在上一步中,我们已经将这些路由的资源都预先下载与缓存好了,那么懒加载就几乎是瞬时完成的了,这时候我们就只需要付出实例化的代价。
至此,我们对PRPL的四部分含义做了详细说明。有趣的是,我们发现多页应用在实现PRPL这件事甚至比单页还要容易一些。那么结果如何呢?
根据Google推出的Web性能分析工具Lighthouse(v1.6),在模拟的3G网络下,用户的初次访问(无任何缓存)大约在2秒左右达到“可交互”,可以说非常不错,见图3所示。而对于再次访问,由于所有资源都直接来自于Service Worker缓存,页面可以在1秒左右就达到可交互的状态了。

图3 Lighthouse跑分结果
但是,故事并不是这么简单得就结束了。在实际体验中我们发现,应用在页与页的切换时,仍然存在着非常明显的白屏空隙,见图4所示。由于PWA是全屏运行,白屏对用户体验所带来的负面影响甚至比以往在浏览器内更大。我们不是已经用Service Worker缓存了所有资源了吗,怎么还会这样呢?
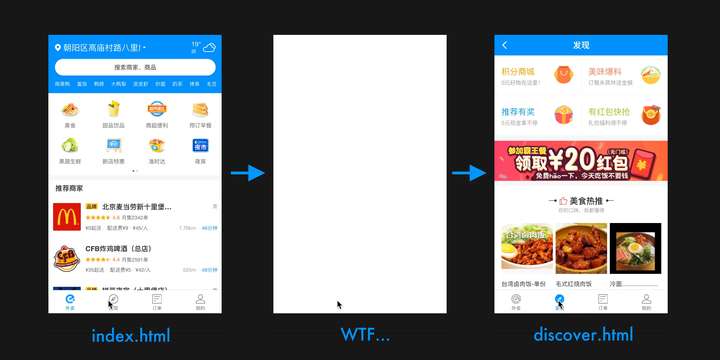
图4 从首页点击到发现页,跳转过程中的白屏
多页应用的陷阱:重启开销
与SPA不同,在多页应用中,路由的切换是原生的浏览器文档跳转(Navigating across documents),这意味着之前的页面会被完全丢弃而浏览器需要为下一个路由的页面重新执行所有的启动步骤:重新下载资源、重新解析HTML、重新运行JavaScript、重新解码图片、重新布局页面、重新绘制……即使其中的很多步骤本是可以在多个路由之间复用的。这些工作无疑将产生巨大的计算开销,也因此需要付出相当多的时间成本。
图5中为我们的入口页(同时也是最重要的页面)在两倍CPU节流模拟下的Profile数据。即使我们可以将“可交互时间”控制在 1 秒左右,我们的用户仍然会觉得这对于“仅仅切换个标签”来说实在是太慢了。
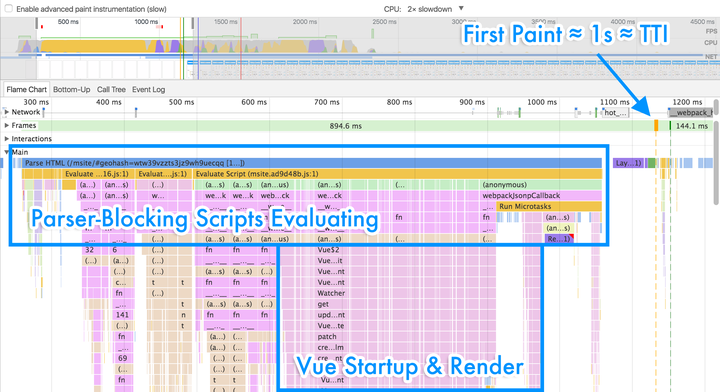
图5 入口页在两倍CPU节流模拟下的Profile数据
巨大的JavaScript重启开销
根据Profile,我们发现在首次渲染(First Paint)发生之前,大量的时间(900ms)都消耗在了JavaScript的运行上(Evaluate Script)。几乎所有脚本都是阻塞的(Parser-blocking),不过因为所有的UI都是由JavaScript/Vue.js驱动的,倒也不会有性能影响。这900ms中,约一半是消耗在Vue.js运行时、组件、库等依赖的运行上,而另一半则花在了业务组件实例化时Vue.js的启动与渲染上。从软件工程角度来说,我们需要这些抽象,所以这里并不是想责怪JavaScript或是Vue.js所带来的开销。
但是,在SPA中, JavaScript的启动成本是均摊到整个生命周期的:每个脚本都只需要被解析与编译一次,诸如生成Virtual DOM等较重的任务可以只执行一次,像Vue.js的ViewModel或是Virtual DOM这样的大对象也可以被留在内存里复用。可惜在多页应用里就不是这样了,我们每次切换页面都为JavaScript付出了巨大的重启代价。
浏览器的缓存啊,能不能帮帮忙?
能,也不能。
V8提供了代码缓存(code caching),可以将编译后的机器码在本地拷贝一份,这样我们就可以在下次请求同一个脚本时一次省略掉请求、解析、编译的所有工作。而且,对于缓存在Service Worker配套的Cache Storage中的脚本,会在第一次执行后就触发V8的代码缓存,这对于我们的多页切换能提供不少帮助。
另外一个你或许听过的浏览器缓存叫做“进退缓存”, Back-Forward Cache,简称bfcache。浏览器厂商对其的命名各异, Opera称之为Fast History Navigation, Webkit称其为Page Cache。但是思路都一样,就是我们可以让浏览器在跳转时把前一页留存在内存中,保留JavaScript与DOM的状态,而不是全都销毁掉。你可以随便找个传统的多页网站在iOS Safari上试试,无论是通过浏览器的前进后退按钮、手势,还是通过超链接(会有一些不同),基本都可以看到瞬间加载的效果。
Bfcache其实非常适合多页应用。但不幸的是,Chrome由于内存开销与其多进程架构等原因目前并不支持。 Chrome现阶段仅仅只是用了传统的HTTP磁盘缓存,来稍稍简化了一下加载过程而已。对于Chromium内核霸占的Android生态来说,我们没法指望了。
为“感知体验”奋斗
尽管多页应用面临着现实中的不少性能问题,我们并不想这么快就妥协。一方面,我们尝试尽可能减少在页面达到可交互时间前的代码执行量,比如减少/推迟一些依赖脚本的执行,还有减少初次渲染的DOM节点数以节省Virtual DOM的初始化开销。另一方面,我们也意识到应用在感知体验上还有更多的优化空间。
Chrome产品经理Owen写过一篇Reactive Web Design: The secret to building web apps that feel amazing,谈到两种改进感知体验的手段:一是使用骨架屏(Skeleton Screen)来实现瞬间加载;二是预先定义好元素的尺寸来保证加载的稳定。跟我们的做法可以说不谋而合。
为了消除白屏时间,我们同样引入了尺寸稳定的骨架屏来帮助我们实现瞬间的加载与占位。即使是在硬件很弱的设备上,我们也可以在点击切换标签后立刻渲染出目标路由的骨架屏,以保证UI是稳定、连续、有响应的。我录了两个视频放在Youtube上,不过如果你是国内读者,你可以直接访问饿了么移动网站来体验实地的效果。最终效果如图6所示。
为“感知体验”奋斗
尽管多页应用面临着现实中的不少性能问题,我们并不想这么快就妥协。一方面,我们尝试尽可能减少在页面达到可交互时间前的代码执行量,比如减少/推迟一些依赖脚本的执行,还有减少初次渲染的DOM节点数以节省Virtual DOM的初始化开销。另一方面,我们也意识到应用在感知体验上还有更多的优化空间。
Chrome产品经理Owen写过一篇Reactive Web Design: The secret to building web apps that feel amazing,谈到两种改进感知体验的手段:一是使用骨架屏(Skeleton Screen)来实现瞬间加载;二是预先定义好元素的尺寸来保证加载的稳定。跟我们的做法可以说不谋而合。
为了消除白屏时间,我们同样引入了尺寸稳定的骨架屏来帮助我们实现瞬间的加载与占位。即使是在硬件很弱的设备上,我们也可以在点击切换标签后立刻渲染出目标路由的骨架屏,以保证UI是稳定、连续、有响应的。我录了两个视频放在Youtube上,不过如果你是国内读者,你可以直接访问饿了么移动网站来体验实地的效果。最终效果如图6所示。
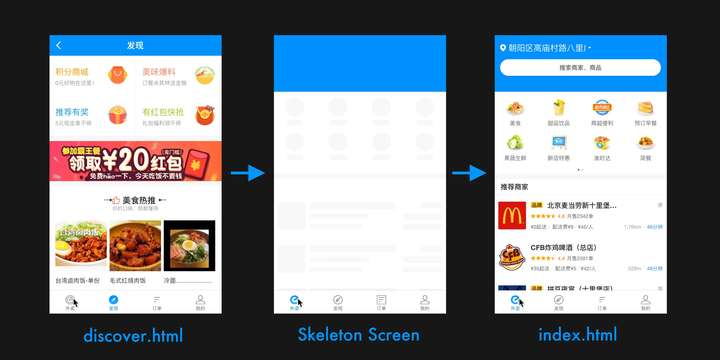
图6 在添加骨架屏后,从发现页点回首页的效果
这效果本该很轻松的就能实现,不过实际上我们还费了点功夫。
在构建时使用 Vue 预渲染骨架屏
你可能已经想到了,为了让骨架屏可以被Service Worker缓存,瞬间加载并独立于JavaScript渲染,我们需要把组成骨架屏的HTML标签、 CSS样式与图片资源一并内联至各个路由的静态*.html文件中。
不过,我们并不准备手动编写这些骨架屏。你想啊,如果每次真实组件有迭代(每一个路由对我们来说都是一个Vue.js组件),我们都需要手动去同步每一个变化到骨架屏的话,那实在是太繁琐且难以维护了。好在,骨架屏不过是当数据还未加载进来前,页面的一个空白版本而已。如果我们能将骨架屏实现为真实组件的一个特殊状态——“空状态”的话,从理论上就可以从真实组件中直接渲染出骨架屏来。
而Vue.js的多才多艺就在这时体现出来了,我们真的可以用Vue.js 的服务端渲染模块来实现这个想法,不过不是用在真正的服务器上,而是在构建时用它把组件的空状态预先渲染成字符串并注入到HTML模板中。你需要调整Vue.js组件代码使得它可以在Node上执行,有些页面对DOM/BOM的依赖一时无法轻易去除得,我们目前只好额外编写一个*.shell.vue来暂时绕过这个问题。
关于浏览器的绘制(Painting)
HTML文件中有标签并不意味着这些标签就能立刻被绘制到屏幕上,你必须保证页面的关键渲染路径是为此优化的。很多开发者相信将Script标签放在body的底部就足以保证内容能在脚本执行之前被绘制,这对于能渲染不完整DOM树的浏览器(比如桌面浏览器常见的流式渲染)来说可能是成立的。但移动端的浏览器很可能因为考虑到较慢的硬件、电量消耗等因素并不这么做。不仅如此,即使你曾被告知设为async或defer的脚本就不会阻塞HTML解析了,但这可不意味着浏览 器就一定会在执行它们之前进行渲染。
首先我想澄清的是,根据 HTML 规范 Scripting 章节, async脚本是在其请求完成后立刻运行的,因此它本来就可能阻塞到解析。只有defer(且非内联)与最新的type=module被指定为“一定不会阻塞解析”(不过defer目前也有点小问题……我们稍后会再提到),见图7所示。

图7 具有不同属性的Script脚本对HTML解析的阻塞情况
而更重要的是,一个不阻塞HTML解析的脚本仍然可能阻塞到绘制。我做了一个简化的“最小多页PWA”(Minimal Multi-page PWA,或MMPWA)来测试这个问题:我们在一个async(且确实不阻塞HTML解析)脚本中,生成并渲染1000个列表项,然后测试骨架屏能否在脚本执行之前渲染出来。图8是通过USB Debugging在我的Nexus 5真机上录制的Profile。
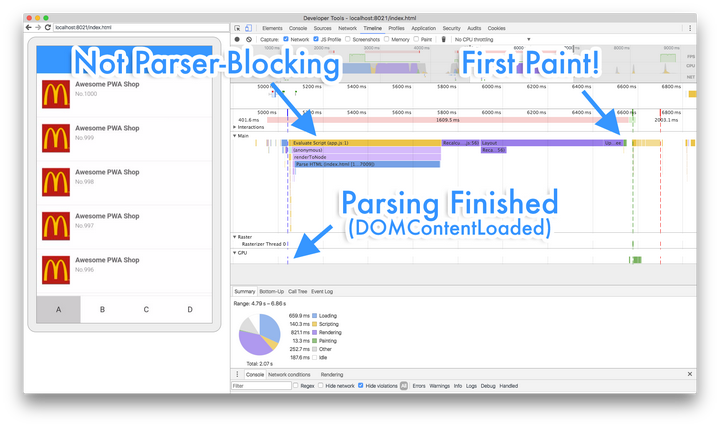
图8 通过USB Debugging在Nexus 5真机上录制的Profile
是的,出乎意料吗?首次渲染确实被阻塞到脚本执行结束后才发生。究其原因,如果我们在浏览器还未完成上一次绘制工作之前就过快得进行了DOM操作,我们亲爱的浏览器就只好抛弃所有它已经完成的像素,且一直要等待到DOM操作引起的所有工作结束之后才能重新进行下一次渲染。而这种情况更容易在拥有较慢CPU/GPU的移动设备上出现。
黑魔法:利用setTimeout()让绘制提前
不难发现,骨架屏的绘制与脚本执行实际是一个竞态。大概是Vue.js太快了,我们的骨架屏还是有非常大的概率绘制不出来。于是我们想着如何能让脚本执行慢点,或者说,“懒”点。于是我们想到了一个经典的Hack: setTimeout(callback, 0)。我们试着把MMPWA中的DOM操作(渲染1000个列表)放进setTimeout(callback, 0)里……
当当!首次渲染瞬间就被提前了,见图9所示。如果你熟悉浏览器的事件循环模型(Event Loop)的话,这招Hack其实是通过setTimeout的回调把DOM操作放到了事件循环的任务队列中以避免它在当前循环执行,这样浏览器就得以在主线程空闲时喘息一下(更新一下渲染)了。如果你想亲手试试 MMPWA的话,你可以访问github.com/Huxpro/mmpwa 或huangxuan.me/mmpwa/ ,查看代码与Demo。我把UI设计成了A/B Test的形式并改为渲染5000个列表项来让效果更夸张一些。
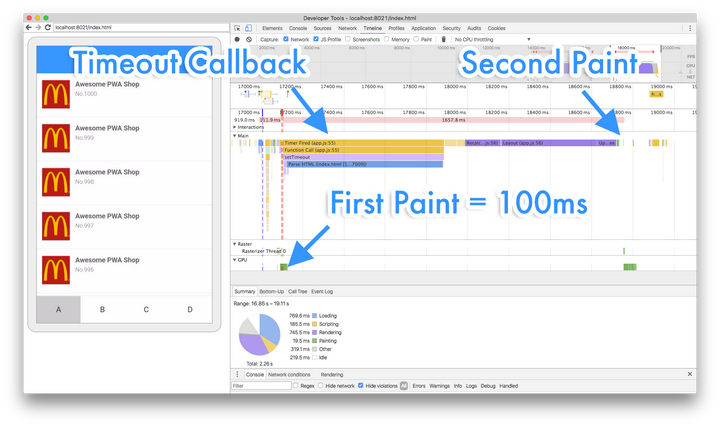
图9 利用Hack技术,提前完成骨架屏的绘制
回到饿了么PWA上,我们同样试着把new Vue()放到了setTimeout中。果然,黑魔法再次显灵,骨架屏在每次跳转后都能立刻被渲染。这时的Profile看起来是这样的,见图10所示。
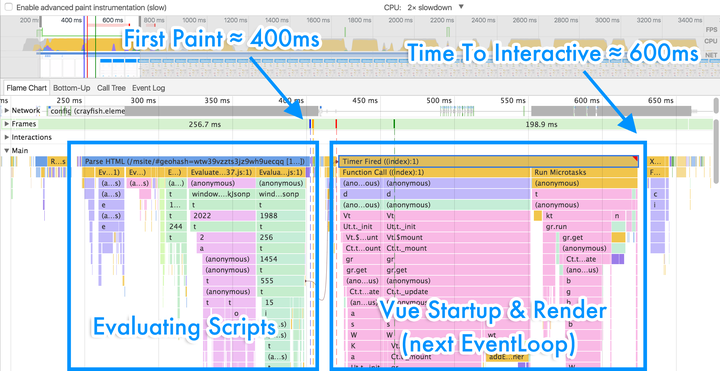
图10 为感知体验进行各种优化后的最终Profile
现在,我们在400ms时触发首次渲染(骨架屏),在600ms时完成真实UI的渲染并达到页面的可交互。你可以详细对比下图9和图10所示的优化前后Profile的区别。
被我“defer”的有关defer的Bug
不知道你发现没有,在图10的Profile中,我们仍然有不少脚本是阻塞了HTML解析的。好吧,让我解释一下,由于历史原因,我们确实保留了一部分的阻塞脚本,比如侵入性很强的lib-flexible,我们没法轻易去除它。不过, Profile里的大部分阻塞脚本实际上都设置了defer,我们本以为他们应该在HTML解析完成之后才被执行,结果被Profile打了一脸。
我和Jake Archibald 聊了一下,果然这是Chrome的Bug: defer的脚本被完全缓存时,并没有遵守规范等待解析结束,反而阻塞了解析与渲染。Jake已经提交在crbug上了,一起给它投票吧。
最后,图11是优化后的Lighthouse跑分结果,同样可以看到明显的性能提升。需要说明的是,能影响Lighthouse跑分的因素有很多,所以我建议你以控制变量(跑分用的设备、跑分时的网络环境等)的方式来进行对照实验。

图11 优化后的Lighthouse跑分结果
最后为大家展示下应用的架构示意图,见图12所示。
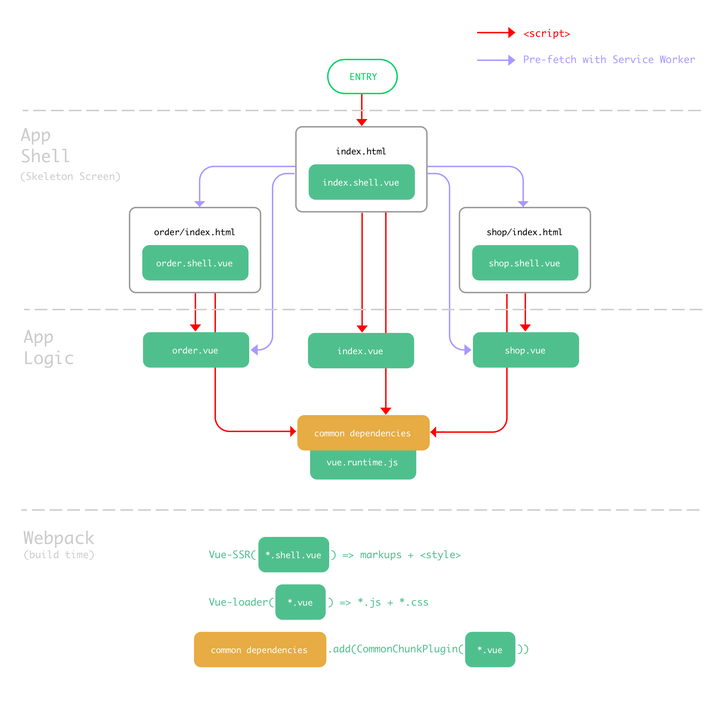
图12 应用架构示意图
一些感想
多页应用仍然有很长的路要走
Web是一个极其多样化的平台。从静态的博客,到电商网站,再到桌面级的生产力软件,它们全都是Web这个大家庭的第一公民。而我们组织Web应用的方式,也同样只会更多而不会更少:多页、单页、 Universal JavaScript应用、 WebGL,以及可以预见的Web Assembly。不同的技术之间没有贵贱,但是适用场景的差距确是客观存在的。
Jake 曾在 Chrome Dev Summit 2016 上说过“PWA!== SPA”。可是尽管我们已经用上了一系列最新的技术(PRPL、 Service Worker、 App Shell……),我们仍然因为多页应用模型本身的缺陷有着难以逾越的一些障碍。多页应用在未来可能会有“bfcache API”、 Navigation Transition等新的规范以缩小跟SPA的距离,不过我们也必须承认,时至今日,多页应用的局限性也是非常明显的。
而PWA终将带领Web应用进入新的时代
即使我们的多页应用在升级PWA的路上不如单页应用来得那么闪亮,但是PWA背后的想法与技术却实实在在地帮助我们在Web平台上提供了更好的用户体验。
PWA作为下一代 Web 应用模型,其尝试解决的是Web平台本身的根本性问题:对网络与浏览器UI的硬依赖。因此,任何Web应用都可以从中获益,这与你是多页还是单页、面向桌面还是移动端、是用React还是Vue.js无关。或许,它还终将改变用户对移动Web的期待。现如今,谁还觉得桌面端的Web只是个看文档的地方呢?
还是那句老话,让我们的用户,也像我们这般热爱Web吧。
最后,感谢饿了么的王亦斯、任光辉、题叶,Google 的 Michael Yeung、 DevRel 团队, UC浏览器团队,腾讯X5浏览器团队在这次项目中的合作。感谢尤雨溪、陈蒙迪和Jake Archibald 在写作过程中给予我的帮助。
原文阅读:https://zhuanlan.zhihu.com/p/27836133
奇葩字符 "a๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎" 的简单分析
前端开发 • zkbhj 发表了文章 • 0 个评论 • 2916 次浏览 • 2018-01-26 09:57
复制这个字符在控制台查看 "a๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎".length 发现他的长度是 20,怎么会是20呢?
我们依次调试 "a๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎".charAt(0), "a๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎".charAt(1), "a๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎".charAt(2) 可以发现第一个字符是a 后面都是其他什么东西组成的。
当你黏贴到notepad++之类的编辑器里,也会发现这个问题,后台那些是重复的字符,而且都可以看到。
这些字符到底是什么东西呢?
突然想起js圣经上貌似记载过一个 é 字符,他的 unicode 是 \u00e9, 但是也可以用 'e' + '\u0301' 实现 "é" 前者 length 是 1,后者 length 是 2。'\u0301' 在这里起到了语调符的作用,然后我就丧心病狂的 'e'+Array(20).join('\u0301'); 发现竟然成功了,果然是这个东西,但是这个语调符有哪些呢。
继续寻找答案,在圣经的注释里发现了他貌似属于 Mn 类,去unicode官方找这个东西,一番寻找后终于找到他了,详情请参阅。
这里解释了 Mn 其实是 a nonspacing combining mark (zero advance width) (谷歌翻译: 一个非空格组合标志(零超前宽度))。
虽然给了解释,但是还是没有说他有那些字符啊,所以我继续寻找答案,功夫不负有心人,终于找到了一张表。
Unicode Characters in the 'Mark, Nonspacing' Category
这里详细的列出了每个编码以及对应的意思,还有图片展现。你可以点击头部那个 View all images 超链接,这样你就不必一个一个展开看图片了。
找到这个的时候我欣喜诺狂,各种测试,发现不仅仅是向上,还有 向左,向下的,但是暂时没发现向右的。
这里面有很多符号,虽然不知道他们在什么情况下使用,但是我的目的达到了,后续的东西暂时没欲望刨根问底了。
下面是我找的几个方向的小尾巴,大家也可以自己去各种测试起来。。
'呵呵'+Array(20).join('\u0310'); // "呵呵̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐"
'呵呵'+Array(20).join('\u031D'); // "呵呵̝̝̝̝̝̝̝̝̝̝̝̝̝̝̝̝̝̝̝"
'呵呵'+Array(20).join('\u0E47'); // "呵呵็็็็็็็็็็็็็็็็็็็"
'呵呵'+Array(20).join('\u0e49'); // "呵呵้้้้้้้้้้้้้้้้้้้"
'呵呵'+Array(20).join('\u0598'); // "呵呵֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘"
也可以这么玩...
'呵呵'+Array(20).join('\u0310')+Array(20).join('\u0598')+Array(20).join('\u0e49'); // "呵呵้้้้้้้้้้้้้้้้้้้̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘" 查看全部
复制这个字符在控制台查看 "a๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎".length 发现他的长度是 20,怎么会是20呢?
我们依次调试 "a๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎".charAt(0), "a๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎".charAt(1), "a๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎๎".charAt(2) 可以发现第一个字符是a 后面都是其他什么东西组成的。
当你黏贴到notepad++之类的编辑器里,也会发现这个问题,后台那些是重复的字符,而且都可以看到。
这些字符到底是什么东西呢?
突然想起js圣经上貌似记载过一个 é 字符,他的 unicode 是 \u00e9, 但是也可以用 'e' + '\u0301' 实现 "é" 前者 length 是 1,后者 length 是 2。'\u0301' 在这里起到了语调符的作用,然后我就丧心病狂的 'e'+Array(20).join('\u0301'); 发现竟然成功了,果然是这个东西,但是这个语调符有哪些呢。
继续寻找答案,在圣经的注释里发现了他貌似属于 Mn 类,去unicode官方找这个东西,一番寻找后终于找到他了,详情请参阅。
这里解释了 Mn 其实是 a nonspacing combining mark (zero advance width) (谷歌翻译: 一个非空格组合标志(零超前宽度))。
虽然给了解释,但是还是没有说他有那些字符啊,所以我继续寻找答案,功夫不负有心人,终于找到了一张表。
Unicode Characters in the 'Mark, Nonspacing' Category
这里详细的列出了每个编码以及对应的意思,还有图片展现。你可以点击头部那个 View all images 超链接,这样你就不必一个一个展开看图片了。
找到这个的时候我欣喜诺狂,各种测试,发现不仅仅是向上,还有 向左,向下的,但是暂时没发现向右的。
这里面有很多符号,虽然不知道他们在什么情况下使用,但是我的目的达到了,后续的东西暂时没欲望刨根问底了。
下面是我找的几个方向的小尾巴,大家也可以自己去各种测试起来。。
'呵呵'+Array(20).join('\u0310'); // "呵呵̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐"
'呵呵'+Array(20).join('\u031D'); // "呵呵̝̝̝̝̝̝̝̝̝̝̝̝̝̝̝̝̝̝̝"
'呵呵'+Array(20).join('\u0E47'); // "呵呵็็็็็็็็็็็็็็็็็็็"
'呵呵'+Array(20).join('\u0e49'); // "呵呵้้้้้้้้้้้้้้้้้้้"
'呵呵'+Array(20).join('\u0598'); // "呵呵֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘"
也可以这么玩...
'呵呵'+Array(20).join('\u0310')+Array(20).join('\u0598')+Array(20).join('\u0e49'); // "呵呵้้้้้้้้้้้้้้้้้้้̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐̐֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘֘"
项目调研:Swagger在PHP项目中的使用实践
工具软件 • zkbhj 发表了文章 • 0 个评论 • 3790 次浏览 • 2018-01-17 12:17
上一篇说的那么官方的介绍,但是这个swagger到底是个什么鬼呢?其实,说白了理解起来也很简单:
其实就是安装Swagger套件, 然后API代码里写注释, 用Swagger后端程序跑API来提取注释, 生成一个json文件(或者YAML), 再通关Swagger前端来美化,整理JSON数据.
所以,看到这里,我们就知道了。要使用Swagger需要安装2个东西:
前端,用来显示;后端, 用来生成JSON
1, 安装前端
swagger-ui下载
git clone https://github.com/swagger-api/swagger-ui.git下载之后找到dist目录, 打开index.html把其中的那一串url改成自己的, 比如 http//localhost/yii2/swagger-docs/swagger.json
$(function () {
var url = window.location.search.match(/url=([^&]+)/);
if (url && url.length > 1) {
url = decodeURIComponent(url[1]);
} else {
url = "http://localhost/yii2/swagger- ... 3B%3B
}还可以把界面调整成中文, 放开js文件的注释即可
<script src='lang/translator.js' type='text/javascript'></script>
<!-- <script src='lang/ru.js' type='text/javascript'></script> -->
<script src='lang/zh-cn.js' type='text/javascript'></script>然后打开URL就可以看到前端界面了, 应该是没内容的, 因为还没生成swagger.json, 生成好之后你设置的URL就起了作用, 直接访问前端就好
http://localhost/yii2/swagger-ui/dist/index.html2, 安装后端
git clone https://github.com/zircote/swagger-php.git因为公司用的是yii2, 所以使用了composer来安装
"require": { "zircote/swagger-php": "*" }之后composer update, 或者直接命令行, 详见官方安装指南。
DCdeMacBook-Pro:yii2 DC$ php composer.phar require zircote/swagger-php把swagger-php放在根目录下,然后用官方提供的Examples来生成测试json
cd swagger-php
mkdir doc
php swagger.phar Examples -o doc"-o" 前面代表API源目录, 即你想要生成哪个目录的API文档, 你的项目代码目录. "-o" 后面是生成到哪个path。我没有进入到swagger-php下面, 直接打的命令行, 任意路径下都可以执行生成json操作
php /Users/DC/www/yii2/vendor/zircote/swagger-php/bin/swagger /Users/DC/www/yii2/vendor/zircote/swagger-php/Examples -o /Users/DC/www/yii2/swagger-docs
然后再看http//localhost/yii2/swagger-ui/dist/index.html, 生成了API文档。
准备工作都做好了, 那就写代码注释就行了, 注释怎么写? 官方参考文档
比如Model:
/**
* @SWG\Model(
* id="vps",
* required="['type', 'hostname']",
* @SWG\Property(name="hostname", type="string"),
* @SWG\Property(name="label", type="string"),
* @SWG\Property(name="type", type="string", enum="['vps', 'dedicated']")
* )
*/
class HostVps extends Host implements ResourceInterface
{
// ...
}
比如Controller:
/**
* @SWG\Resource(
* basePath="http://skyapi.dev",
* resourcePath="/vps",
* @SWG\Api(
* path="/vps",
* @SWG\Operation(
* method="GET",
* type="array",
* summary="Fetch vps lists",
* nickname="vps/index",
* @SWG\Parameter(
* name="expand",
* description="Models to expand",
* paramType="query",
* type="string",
* defaultValue="vps,os_template"
* )
* )
* )
* )
*/
class VpsController extends Controller
{
// ...
}每次改动API代码注释之后都要手动生成json文件? 太麻烦了, 写了个controller, 每次访问swagger-ui的这个controller, 先生成json再跳转到ui页面。
$b2broot = Yii::getAlias('@b2broot');
$swagger = \Swagger\scan($b2broot.'/myapi');
$json_file = $b2broot.'/swagger-docs/swagger.json';
$is_write = file_put_contents($json_file, $swagger);
if ($is_write == true) {
$this->redirect('http//localhost/yii2/swagger-ui/dist/index.html');
}参考文档:
https://www.cnblogs.com/handongyu/p/6992367.html
查看全部
上一篇说的那么官方的介绍,但是这个swagger到底是个什么鬼呢?其实,说白了理解起来也很简单:
其实就是安装Swagger套件, 然后API代码里写注释, 用Swagger后端程序跑API来提取注释, 生成一个json文件(或者YAML), 再通关Swagger前端来美化,整理JSON数据.
所以,看到这里,我们就知道了。要使用Swagger需要安装2个东西:
- 前端,用来显示;
- 后端, 用来生成JSON
1, 安装前端
swagger-ui下载
git clone https://github.com/swagger-api/swagger-ui.git下载之后找到dist目录, 打开index.html把其中的那一串url改成自己的, 比如 http//localhost/yii2/swagger-docs/swagger.json
$(function () {
var url = window.location.search.match(/url=([^&]+)/);
if (url && url.length > 1) {
url = decodeURIComponent(url[1]);
} else {
url = "http://localhost/yii2/swagger- ... 3B%3B
}还可以把界面调整成中文, 放开js文件的注释即可<script src='lang/translator.js' type='text/javascript'></script>然后打开URL就可以看到前端界面了, 应该是没内容的, 因为还没生成swagger.json, 生成好之后你设置的URL就起了作用, 直接访问前端就好
<!-- <script src='lang/ru.js' type='text/javascript'></script> -->
<script src='lang/zh-cn.js' type='text/javascript'></script>
http://localhost/yii2/swagger-ui/dist/index.html2, 安装后端
git clone https://github.com/zircote/swagger-php.git因为公司用的是yii2, 所以使用了composer来安装
"require": { "zircote/swagger-php": "*" }之后composer update, 或者直接命令行, 详见官方安装指南。DCdeMacBook-Pro:yii2 DC$ php composer.phar require zircote/swagger-php把swagger-php放在根目录下,然后用官方提供的Examples来生成测试json
cd swagger-php"-o" 前面代表API源目录, 即你想要生成哪个目录的API文档, 你的项目代码目录. "-o" 后面是生成到哪个path。我没有进入到swagger-php下面, 直接打的命令行, 任意路径下都可以执行生成json操作
mkdir doc
php swagger.phar Examples -o doc
php /Users/DC/www/yii2/vendor/zircote/swagger-php/bin/swagger /Users/DC/www/yii2/vendor/zircote/swagger-php/Examples -o /Users/DC/www/yii2/swagger-docs然后再看http//localhost/yii2/swagger-ui/dist/index.html, 生成了API文档。
准备工作都做好了, 那就写代码注释就行了, 注释怎么写? 官方参考文档
比如Model:
/**
* @SWG\Model(
* id="vps",
* required="['type', 'hostname']",
* @SWG\Property(name="hostname", type="string"),
* @SWG\Property(name="label", type="string"),
* @SWG\Property(name="type", type="string", enum="['vps', 'dedicated']")
* )
*/
class HostVps extends Host implements ResourceInterface
{
// ...
}
比如Controller:
/**每次改动API代码注释之后都要手动生成json文件? 太麻烦了, 写了个controller, 每次访问swagger-ui的这个controller, 先生成json再跳转到ui页面。
* @SWG\Resource(
* basePath="http://skyapi.dev",
* resourcePath="/vps",
* @SWG\Api(
* path="/vps",
* @SWG\Operation(
* method="GET",
* type="array",
* summary="Fetch vps lists",
* nickname="vps/index",
* @SWG\Parameter(
* name="expand",
* description="Models to expand",
* paramType="query",
* type="string",
* defaultValue="vps,os_template"
* )
* )
* )
* )
*/
class VpsController extends Controller
{
// ...
}
$b2broot = Yii::getAlias('@b2broot');
$swagger = \Swagger\scan($b2broot.'/myapi');
$json_file = $b2broot.'/swagger-docs/swagger.json';
$is_write = file_put_contents($json_file, $swagger);
if ($is_write == true) {
$this->redirect('http//localhost/yii2/swagger-ui/dist/index.html');
}参考文档:https://www.cnblogs.com/handongyu/p/6992367.html
高性能JavaScript模板引擎:artTemplate原理解析
移动开发 • zkbhj 发表了文章 • 0 个评论 • 2960 次浏览 • 2018-01-12 17:50
artTemplate 是新一代 javascript 模板引擎,它采用预编译方式让性能有了质的飞跃,并且充分利用 javascript 引擎特性,使得其性能无论在前端还是后端都有极其出色的表现。在 chrome 下渲染效率测试中分别是知名引擎 Mustache 与 micro tmpl 的 25 、 32 倍。
除了性能优势外,调试功能也值得一提。模板调试器可以精确定位到引发渲染错误的模板语句,解决了编写模板过程中无法调试的痛苦,让开发变得高效,也避免了因为单个模板出错导致整个应用崩溃的情况发生。
artTemplate 这一切都在 1.7kb(gzip) 中实现!
javascript 模板引擎基本原理
虽然每个引擎从模板语法、语法解析、变量赋值、字符串拼接的实现方式各有所不同,但关键的渲染原理仍然是动态执行 javascript 字符串。
关于动态执行 javascript 字符串,本文以一段模板代码举例:
这是一段非常朴素的模板写法,其中,”” 为 closeTag (逻辑语句闭合标签),若 openTag 后面紧跟 “=” 则会输出变量的内容。
HTML语句与变量输出语句被直接输出,解析后的字符串类似:
语法分析完毕一般还会返回渲染方法:
渲染测试:
在上面 render 方法中,模板变量赋值采用了 with 语句,字符串拼接采用数组的 push 方法以提升在 IE6、7 下的性能,jQuery 作者 john 开发的微型模板引擎 tmpl 是这种方式的典型代表,参见: http://ejohn.org/blog/javascript-micro-templating/
由原理实现可见,传统 javascript 模板引擎中留下两个待解决的问题:
1、性能:模板引擎渲染的时候依赖 Function 构造器实现,Function 与 eval、setTimeout、setInterval 一样,提供了使用文本访问 javascript 解析引擎的方法,但这样执行 javascript 的性能非常低下。
2、调试:由于是动态执行字符串,若遇到错误调试器无法捕获错误源,导致模板 BUG 调试变得异常痛苦。在没有进行容错的引擎中,局部模板若因为数据异常甚至可以导致整个应用崩溃,随着模板的数目增加,维护成本将剧增。
artTemplate 高效的秘密
1、预编译
在上述模板引擎实现原理中,因为要对模板变量进行赋值,所以每次渲染都需要动态编译 javascript 字符串完成变量赋值。而 artTemplate 的编译赋值过程却是在渲染之前完成的,这种方式称之为“预编译”。artTemplate 模板编译器会根据一些简单的规则提取好所有模板变量,声明在渲染函数头部,这个函数类似:
这个自动生成的函数就如同一个手工编写的 javascript 函数一样,同等的执行次数下无论 CPU 还是内存占用都有显著减少,性能近乎极限。
值得一提的是:artTemplate 很多特性都基于预编译实现,如沙箱规范与自定义语法等。
2、更快的字符串相加方式
很多人误以为数组 push 方法拼接字符串会比 += 快,要知道这仅仅是 IE6-8 的浏览器下。实测表明现代浏览器使用 += 会比数组 push 方法快,而在 v8 引擎中,使用 += 方式比数组拼接快 4.7 倍。所以 artTemplate 根据 javascript 引擎特性采用了两种不同的字符串拼接方式。
artTemplate 调试模式原理
前端模板引擎不像后端模板引擎,它是动态解析,所以调试器无法定位到错误行号,而 artTemplate 通过巧妙的方式让模板调试器可以精确定位到引发渲染错误的模板语句,例如:
artTemplate 支持两种类型的错误捕获,一是渲染错误(Render Error)与编译错误(Syntax Error)。
1、渲染错误
渲染错误一般是因为模板数据错误或者变量错误产生的,渲染的时候只有遇到错误才会进入调试模式重新编译模板,而不会影响正常的模板执行效率。模板编译器根据模板换行符记录行号,编译后的函数类似:
当执行过程遇到错误,立马抛出异常模板对应的行号,模板调试器再根据行号反查模板对应的语句并打印到控制台。
2、编译错误
编译错误一般是模板语法错误,如不合格的套嵌、未知语法等。由于 artTemplate 没有进行完整的词法分析,故无法确定错误源所在的位置,只能对错误信息与源码进行原文输出,供开发者判断。
开源节流
artTemplate 基于开源协议发布,无论是商业公司还是个人都可以免费在项目中使用,欢迎共同完善。
下载地址:
https://github.com/aui/artTemplate
在线预览:
http://aui.github.com/artTemplate/ 查看全部
artTemplate 是新一代 javascript 模板引擎,它采用预编译方式让性能有了质的飞跃,并且充分利用 javascript 引擎特性,使得其性能无论在前端还是后端都有极其出色的表现。在 chrome 下渲染效率测试中分别是知名引擎 Mustache 与 micro tmpl 的 25 、 32 倍。

除了性能优势外,调试功能也值得一提。模板调试器可以精确定位到引发渲染错误的模板语句,解决了编写模板过程中无法调试的痛苦,让开发变得高效,也避免了因为单个模板出错导致整个应用崩溃的情况发生。
artTemplate 这一切都在 1.7kb(gzip) 中实现!
javascript 模板引擎基本原理
虽然每个引擎从模板语法、语法解析、变量赋值、字符串拼接的实现方式各有所不同,但关键的渲染原理仍然是动态执行 javascript 字符串。
关于动态执行 javascript 字符串,本文以一段模板代码举例:

这是一段非常朴素的模板写法,其中,”” 为 closeTag (逻辑语句闭合标签),若 openTag 后面紧跟 “=” 则会输出变量的内容。
HTML语句与变量输出语句被直接输出,解析后的字符串类似:

语法分析完毕一般还会返回渲染方法:

渲染测试:

在上面 render 方法中,模板变量赋值采用了 with 语句,字符串拼接采用数组的 push 方法以提升在 IE6、7 下的性能,jQuery 作者 john 开发的微型模板引擎 tmpl 是这种方式的典型代表,参见: http://ejohn.org/blog/javascript-micro-templating/
由原理实现可见,传统 javascript 模板引擎中留下两个待解决的问题:
1、性能:模板引擎渲染的时候依赖 Function 构造器实现,Function 与 eval、setTimeout、setInterval 一样,提供了使用文本访问 javascript 解析引擎的方法,但这样执行 javascript 的性能非常低下。
2、调试:由于是动态执行字符串,若遇到错误调试器无法捕获错误源,导致模板 BUG 调试变得异常痛苦。在没有进行容错的引擎中,局部模板若因为数据异常甚至可以导致整个应用崩溃,随着模板的数目增加,维护成本将剧增。
artTemplate 高效的秘密
1、预编译
在上述模板引擎实现原理中,因为要对模板变量进行赋值,所以每次渲染都需要动态编译 javascript 字符串完成变量赋值。而 artTemplate 的编译赋值过程却是在渲染之前完成的,这种方式称之为“预编译”。artTemplate 模板编译器会根据一些简单的规则提取好所有模板变量,声明在渲染函数头部,这个函数类似:

这个自动生成的函数就如同一个手工编写的 javascript 函数一样,同等的执行次数下无论 CPU 还是内存占用都有显著减少,性能近乎极限。
值得一提的是:artTemplate 很多特性都基于预编译实现,如沙箱规范与自定义语法等。
2、更快的字符串相加方式
很多人误以为数组 push 方法拼接字符串会比 += 快,要知道这仅仅是 IE6-8 的浏览器下。实测表明现代浏览器使用 += 会比数组 push 方法快,而在 v8 引擎中,使用 += 方式比数组拼接快 4.7 倍。所以 artTemplate 根据 javascript 引擎特性采用了两种不同的字符串拼接方式。
artTemplate 调试模式原理
前端模板引擎不像后端模板引擎,它是动态解析,所以调试器无法定位到错误行号,而 artTemplate 通过巧妙的方式让模板调试器可以精确定位到引发渲染错误的模板语句,例如:

artTemplate 支持两种类型的错误捕获,一是渲染错误(Render Error)与编译错误(Syntax Error)。
1、渲染错误
渲染错误一般是因为模板数据错误或者变量错误产生的,渲染的时候只有遇到错误才会进入调试模式重新编译模板,而不会影响正常的模板执行效率。模板编译器根据模板换行符记录行号,编译后的函数类似:

当执行过程遇到错误,立马抛出异常模板对应的行号,模板调试器再根据行号反查模板对应的语句并打印到控制台。
2、编译错误
编译错误一般是模板语法错误,如不合格的套嵌、未知语法等。由于 artTemplate 没有进行完整的词法分析,故无法确定错误源所在的位置,只能对错误信息与源码进行原文输出,供开发者判断。
开源节流
artTemplate 基于开源协议发布,无论是商业公司还是个人都可以免费在项目中使用,欢迎共同完善。
下载地址:
https://github.com/aui/artTemplate
在线预览:
http://aui.github.com/artTemplate/
JSON传输二进制数据
前端开发 • zkbhj 发表了文章 • 0 个评论 • 4035 次浏览 • 2018-01-11 12:25
本文提供一种思路给大家参考,让大家可以在json传输二进制文件,如果大家有这个需求又不知怎么实现的话,也许本文能够帮到你。思想适用于所有语言,本文以java实现,相信大家很容易就能转化为自己懂得语言。
思路
1. 读取二进制文件到内存
2. 用Gzip压缩一下。毕竟是在网络传输嘛,当然你也可以不压缩。
3. 用Base64 把byte[] 转成字符串
补充:什么是Base64
以下摘自阮一峰博客,Base64的具体编码方式,大家可以直接进入。
Base64是一种编码方式,它可以将8位的非英语字符转化为7位的ASCII字符。这样的初衷,是为了满足电子邮件中不能直接使用非ASCII码字符的规定,但是也有其他重要的意义:
a)所有的二进制文件,都可以因此转化为可打印的文本编码,使用文本软件进行编辑;
b)能够对文本进行简单的加密。
实现
主要思路就是以上3步,把字符串添加到json字段后发给服务端,然后服务器再用Base64解密–>Gzip解压,就能得到原始的二进制文件了。是不是很简单呢?说了不少,下面我们来看看具体的代码实现。/**
* @author xing
*/
public class TestBase64 {
public static void main(String[] args) {
byte[] data = compress(loadFile());
String json = new String(Base64.encodeBase64(data));
System.out.println("data length:" + json.length());
}
/**
* 加载本地文件,并转换为byte数组
* @return
*/
public static byte[] loadFile() {
File file = new File("d:/11.jpg");
FileInputStream fis = null;
ByteArrayOutputStream baos = null;
byte[] data = null ;
try {
fis = new FileInputStream(file);
baos = new ByteArrayOutputStream((int) file.length());
byte[] buffer = new byte[1024];
int len = -1;
while ((len = fis.read(buffer)) != -1) {
baos.write(buffer, 0, len);
}
data = baos.toByteArray() ;
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fis != null) {
fis.close();
fis = null;
}
baos.close() ;
} catch (IOException e) {
e.printStackTrace();
}
}
return data ;
}
/**
* 对byte[]进行压缩
*
* @param 要压缩的数据
* @return 压缩后的数据
*/
public static byte[] compress(byte[] data) {
System.out.println("before:" + data.length);
GZIPOutputStream gzip = null ;
ByteArrayOutputStream baos = null ;
byte[] newData = null ;
try {
baos = new ByteArrayOutputStream() ;
gzip = new GZIPOutputStream(baos);
gzip.write(data);
gzip.finish();
gzip.flush();
newData = baos.toByteArray() ;
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
gzip.close();
baos.close() ;
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("after:" + newData.length);
return newData ;
}
} 最后输出了一下字符串长度,大家也许觉得经过压缩也没降低多少体积嘛。但大家可以试试不用gzip,你会发现经过转换的字符串比原来大多了。没办法,这是由Base64的算法决定的。所以嘛,还是压缩一下好。
本文所使用的方法比较简单,大家如果有更好或者觉得有更好的方式,不妨一起探讨一下。
【服务端传输】
我们都知道json是文本格式.所以我马上想到的是把文件编码成文本,再进行传输. 所以关键就是要把一个二进制文件翻译成文本,再翻译回去.如果可以,也就代表这个方案是可行的. 马上我就写出了第一个版本:
// 读取文件
FileInputStream fileInputStream = new FileInputStream("d:/a.png");
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
int i;
while ((i = fileInputStream.read()) != -1) {
byteArrayOutputStream.write(i);
}
fileInputStream.close();
// 把文件存在一个字节数组中
byte[] filea = byteArrayOutputStream.toByteArray();
byteArrayOutputStream.close();
String fileaString = new String(filea);
System.out.println(fileaString);
// 写入文件
FileOutputStream fileOutputStream = new FileOutputStream("d:/b.png");
fileOutputStream.write(fileaString.getBytes());
fileOutputStream.flush();
fileOutputStream.close();
发现b.png根本无法打开,很是奇怪?而且大小也不一样了. 检查代码后发现把数组转化成string的时候后面还可以加个参数charset[编码名称].
于是马上改了一下: .......
String fileaString = new String(filea,"uft-8");
.......
fileOutputStream.write(fileaString.getBytes("utf-8"));
结果还是不行,又改了一下: .......
String fileaString = new String(filea,"ISO-8859-1");
.......
fileOutputStream.write(fileaString.getBytes("ISO-8859-1"));
结果成功了.
结合以前的编码知识,总算是想明白了:
把字节数组转换成字符串时,如果charset为空,那就表示用你的默认编码进行转换.
而不管gb2312和utf8都不是用单字节表示一个字符的.只要他不认识的,他就会默认转换成一个特定字符,所以这样的转换是不可逆的.
只有像ascii这样的单字节编码的转换才是可逆的.
明白了这个道理.我们就可以用json协议来传任何的数据了.^_^,大功告成!
有关编码的问题我推荐阮一峰的一篇博文,对字符编码有很好的解释.
http://www.ruanyifeng.com/blog ... .html
查看全部
本文提供一种思路给大家参考,让大家可以在json传输二进制文件,如果大家有这个需求又不知怎么实现的话,也许本文能够帮到你。思想适用于所有语言,本文以java实现,相信大家很容易就能转化为自己懂得语言。
思路
1. 读取二进制文件到内存
2. 用Gzip压缩一下。毕竟是在网络传输嘛,当然你也可以不压缩。
3. 用Base64 把byte[] 转成字符串
补充:什么是Base64
以下摘自阮一峰博客,Base64的具体编码方式,大家可以直接进入。
Base64是一种编码方式,它可以将8位的非英语字符转化为7位的ASCII字符。这样的初衷,是为了满足电子邮件中不能直接使用非ASCII码字符的规定,但是也有其他重要的意义:
a)所有的二进制文件,都可以因此转化为可打印的文本编码,使用文本软件进行编辑;
b)能够对文本进行简单的加密。
实现
主要思路就是以上3步,把字符串添加到json字段后发给服务端,然后服务器再用Base64解密–>Gzip解压,就能得到原始的二进制文件了。是不是很简单呢?说了不少,下面我们来看看具体的代码实现。
/**最后输出了一下字符串长度,大家也许觉得经过压缩也没降低多少体积嘛。但大家可以试试不用gzip,你会发现经过转换的字符串比原来大多了。没办法,这是由Base64的算法决定的。所以嘛,还是压缩一下好。
* @author xing
*/
public class TestBase64 {
public static void main(String[] args) {
byte[] data = compress(loadFile());
String json = new String(Base64.encodeBase64(data));
System.out.println("data length:" + json.length());
}
/**
* 加载本地文件,并转换为byte数组
* @return
*/
public static byte[] loadFile() {
File file = new File("d:/11.jpg");
FileInputStream fis = null;
ByteArrayOutputStream baos = null;
byte[] data = null ;
try {
fis = new FileInputStream(file);
baos = new ByteArrayOutputStream((int) file.length());
byte[] buffer = new byte[1024];
int len = -1;
while ((len = fis.read(buffer)) != -1) {
baos.write(buffer, 0, len);
}
data = baos.toByteArray() ;
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (fis != null) {
fis.close();
fis = null;
}
baos.close() ;
} catch (IOException e) {
e.printStackTrace();
}
}
return data ;
}
/**
* 对byte[]进行压缩
*
* @param 要压缩的数据
* @return 压缩后的数据
*/
public static byte[] compress(byte[] data) {
System.out.println("before:" + data.length);
GZIPOutputStream gzip = null ;
ByteArrayOutputStream baos = null ;
byte[] newData = null ;
try {
baos = new ByteArrayOutputStream() ;
gzip = new GZIPOutputStream(baos);
gzip.write(data);
gzip.finish();
gzip.flush();
newData = baos.toByteArray() ;
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
gzip.close();
baos.close() ;
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("after:" + newData.length);
return newData ;
}
}
本文所使用的方法比较简单,大家如果有更好或者觉得有更好的方式,不妨一起探讨一下。
【服务端传输】
我们都知道json是文本格式.所以我马上想到的是把文件编码成文本,再进行传输. 所以关键就是要把一个二进制文件翻译成文本,再翻译回去.如果可以,也就代表这个方案是可行的. 马上我就写出了第一个版本:
// 读取文件发现b.png根本无法打开,很是奇怪?而且大小也不一样了. 检查代码后发现把数组转化成string的时候后面还可以加个参数charset[编码名称].
FileInputStream fileInputStream = new FileInputStream("d:/a.png");
ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream();
int i;
while ((i = fileInputStream.read()) != -1) {
byteArrayOutputStream.write(i);
}
fileInputStream.close();
// 把文件存在一个字节数组中
byte[] filea = byteArrayOutputStream.toByteArray();
byteArrayOutputStream.close();
String fileaString = new String(filea);
System.out.println(fileaString);
// 写入文件
FileOutputStream fileOutputStream = new FileOutputStream("d:/b.png");
fileOutputStream.write(fileaString.getBytes());
fileOutputStream.flush();
fileOutputStream.close();
于是马上改了一下:
.......
String fileaString = new String(filea,"uft-8");
.......
fileOutputStream.write(fileaString.getBytes("utf-8"));
结果还是不行,又改了一下:
.......
String fileaString = new String(filea,"ISO-8859-1");
.......
fileOutputStream.write(fileaString.getBytes("ISO-8859-1"));
结果成功了.
结合以前的编码知识,总算是想明白了:
把字节数组转换成字符串时,如果charset为空,那就表示用你的默认编码进行转换.
而不管gb2312和utf8都不是用单字节表示一个字符的.只要他不认识的,他就会默认转换成一个特定字符,所以这样的转换是不可逆的.
只有像ascii这样的单字节编码的转换才是可逆的.
明白了这个道理.我们就可以用json协议来传任何的数据了.^_^,大功告成!
有关编码的问题我推荐阮一峰的一篇博文,对字符编码有很好的解释.
http://www.ruanyifeng.com/blog ... .html
回顾HTTP访问控制(CORS)
前端开发 • zkbhj 发表了文章 • 0 个评论 • 2848 次浏览 • 2017-12-22 11:49
比如,站点 http://domain-a.com 的某 HTML 页面通过 <img> 的 src 请求 http://domain-b.com/image.jpg。网络上的许多页面都会加载来自不同域的CSS样式表,图像和脚本等资源。
出于安全原因,浏览器限制从脚本内发起的跨源HTTP请求。 例如,XMLHttpRequest和Fetch API遵循同源策略。 这意味着使用这些API的Web应用程序只能从加载应用程序的同一个域请求HTTP资源,除非使用CORS头文件。
(译者注:这段描述跨域不准确,跨域并不一定是浏览器限制了发起跨站请求,也可能是跨站请求可以正常发起,但是返回结果被浏览器拦截了。最好的例子是 CSRF 跨站攻击原理,请求是发送到了后端服务器无论是否跨域!注意:有些浏览器不允许从 HTTPS 的域跨域访问 HTTP,比如 Chrome 和 Firefox,这些浏览器在请求还未发出的时候就会拦截请求,这是一个特例。)
跨域资源共享标准( cross-origin sharing standard )允许在下列场景中使用跨域 HTTP 请求:
前文提到的由 XMLHttpRequest 或 Fetch 发起的跨域 HTTP 请求。Web 字体 (CSS 中通过 @font-face 使用跨域字体资源), 因此,网站就可以发布 TrueType 字体资源,并只允许已授权网站进行跨站调用。WebGL 贴图使用 drawImage 将 Images/video 画面绘制到 canvas样式表(使用 CSSOM)Scripts (未处理的异常)
本文概述了跨域资源共享机制及其所涉及的 HTTP 首部字段。
概述
跨域资源共享标准新增了一组 HTTP 首部字段,允许服务器声明哪些源站有权限访问哪些资源。另外,规范要求,对那些可能对服务器数据产生副作用的 HTTP 请求方法(特别是 GET 以外的 HTTP 请求,或者搭配某些 MIME 类型的 POST 请求),浏览器必须首先使用 OPTIONS 方法发起一个预检请求(preflight request),从而获知服务端是否允许该跨域请求。服务器确认允许之后,才发起实际的 HTTP 请求。在预检请求的返回中,服务器端也可以通知客户端,是否需要携带身份凭证(包括 Cookies 和 HTTP 认证相关数据)。
接下来的内容将讨论相关场景,并剖析该机制所涉及的 HTTP 首部字段。
若干访问控制场景
这里,我们使用三个场景来解释跨域资源共享机制的工作原理。这些例子都使用 XMLHttpRequest 对象。
简单请求
某些请求不会触发 CORS 预检请求。本文称这样的请求为“简单请求”,请注意,该术语并不属于 Fetch (其中定义了 CORS)规范。若请求满足所有下述条件,则该请求可视为“简单请求”:
1.使用下列方法之一:
GETHEADPOST
2.Fetch 规范定义了对 CORS 安全的首部字段集合,不得人为设置该集合之外的其他首部字段。该集合为:
AcceptAccept-LanguageContent-LanguageContent-Type (需要注意额外的限制)DPRDownlinkSave-DataViewport-WidthWidth
3.Content-Type 的值仅限于下列三者之一:
text/plainmultipart/form-dataapplication/x-www-form-urlencoded
比如说,假如站点 http://foo.example 的网页应用想要访问 http://bar.other 的资源。http://foo.example 的网页中可能包含类似于下面的 JavaScript 代码:var invocation = new XMLHttpRequest();
var url = 'http://bar.other/resources/public-data/';
function callOtherDomain() {
if(invocation) {
invocation.open('GET', url, true);
invocation.onreadystatechange = handler;
invocation.send();
}
}客户端和服务器之间使用 CORS 首部字段来处理跨域权限:
分别检视请求报文和响应报文:GET /resources/public-data/ HTTP/1.1
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Referer: http://foo.example/examples/ac ... .html
Origin: http://foo.example
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 00:23:53 GMT
Server: Apache/2.0.61
Access-Control-Allow-Origin: *
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Transfer-Encoding: chunked
Content-Type: application/xml
[XML Data]第 1~10 行是请求首部。第10行 的请求首部字段 Origin 表明该请求来源于 http://foo.exmaple。
第 13~22 行是来自于 http://bar.other 的服务端响应。响应中携带了响应首部字段 Access-Control-Allow-Origin(第 16 行)。使用 Origin 和 Access-Control-Allow-Origin 就能完成最简单的访问控制。本例中,服务端返回的 Access-Control-Allow-Origin: * 表明,该资源可以被任意外域访问。如果服务端仅允许来自 http://foo.example 的访问,该首部字段的内容如下:
Access-Control-Allow-Origin: http://foo.example
现在,除了 http://foo.example,其它外域均不能访问该资源(该策略由请求首部中的 ORIGIN 字段定义,见第10行)。Access-Control-Allow-Origin 应当为 * 或者包含由 Origin 首部字段所指明的域名。
预检请求
与前述简单请求不同,“需预检的请求”要求必须首先使用 OPTIONS 方法发起一个预检请求到服务器,以获知服务器是否允许该实际请求。"预检请求“的使用,可以避免跨域请求对服务器的用户数据产生未预期的影响。
当请求满足下述任一条件时,即应首先发送预检请求:
1.使用了下面任一 HTTP 方法:
PUTDELETECONNECTOPTIONSTRACEPATCH
2.人为设置了对 CORS 安全的首部字段集合之外的其他首部字段。该集合为:
AcceptAccept-LanguageContent-LanguageContent-Type (but note the additional requirements below)DPRDownlinkSave-DataViewport-WidthWidth
3.Content-Type 的值不属于下列之一:
application/x-www-form-urlencodedmultipart/form-datatext/plain
如下是一个需要执行预检请求的 HTTP 请求:var invocation = new XMLHttpRequest();
var url = 'http://bar.other/resources/post-here/';
var body = '<?xml version="1.0"?><person><name>Arun</name></person>';
function callOtherDomain(){
if(invocation)
{
invocation.open('POST', url, true);
invocation.setRequestHeader('X-PINGOTHER', 'pingpong');
invocation.setRequestHeader('Content-Type', 'application/xml');
invocation.onreadystatechange = handler;
invocation.send(body);
}
}
......上面的代码使用 POST 请求发送一个 XML 文档,该请求包含了一个自定义的请求首部字段(X-PINGOTHER: pingpong)。另外,该请求的 Content-Type 为 application/xml。因此,该请求需要首先发起“预检请求”。
OPTIONS /resources/post-here/ HTTP/1.1
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Origin: http://foo.example
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER, Content-Type
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:15:39 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400
Vary: Accept-Encoding, Origin
Content-Encoding: gzip
Content-Length: 0
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain预检请求完成之后,发送实际请求:POST /resources/post-here/ HTTP/1.1
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
X-PINGOTHER: pingpong
Content-Type: text/xml; charset=UTF-8
Referer: http://foo.example/examples/pr ... .html
Content-Length: 55
Origin: http://foo.example
Pragma: no-cache
Cache-Control: no-cache
<?xml version="1.0"?><person><name>Arun</name></person>
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:15:40 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: http://foo.example
Vary: Accept-Encoding, Origin
Content-Encoding: gzip
Content-Length: 235
Keep-Alive: timeout=2, max=99
Connection: Keep-Alive
Content-Type: text/plain
[Some GZIP'd payload]浏览器检测到,从 JavaScript 中发起的请求需要被预检。从上面的报文中,我们看到,第 1~12 行发送了一个使用 OPTIONS 方法的“预检请求”。 OPTIONS 是 HTTP/1.1 协议中定义的方法,用以从服务器获取更多信息。该方法不会对服务器资源产生影响。 预检请求中同时携带了下面两个首部字段:Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER首部字段 Access-Control-Request-Method 告知服务器,实际请求将使用 POST 方法。
首部字段 Access-Control-Request-Headers 告知服务器,实际请求将携带两个自定义请求首部字段:X-PINGOTHER 与 Content-Type。
服务器据此决定,该实际请求是否被允许。第14~26 行为预检请求的响应,表明服务器将接受后续的实际请求。重点看第 17~20 行:Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400首部字段 Access-Control-Allow-Methods 表明服务器允许客户端使用 POST, GET 和OPTIONS 方法发起请求。该字段与 HTTP/1.1 Allow: response header 类似,但仅限于在需要访问控制的场景中使用。首部字段 Access-Control-Allow-Headers 表明服务器允许请求中携带字段 X-PINGOTHER 与 Content-Type。与 Access-Control-Allow-Methods 一样,Access-Control-Allow-Headers 的值为逗号分割的列表。
最后,首部字段 Access-Control-Max-Age 表明该响应的有效时间为 86400 秒,也就是 24 小时。在有效时间内,浏览器无须为同一请求再次发起预检请求。请注意,浏览器自身维护了一个最大有效时间,如果该首部字段的值超过了最大有效时间,将不会生效。
预检请求与重定向
大多数浏览器不支持针对于预检请求的重定向。如果一个预检请求发生了重定向,浏览器将报告错误:The request was redirected to 'https://example.com/foo', which is disallowed for cross-origin requests that require preflight
Request requires preflight, which is disallowed to follow cross-origin redirectCORS 最初要求该行为,不过在后续的修订中废弃了这一要求。
在浏览器的实现跟上规范之前,有两种方式规避上述报错行为:
在服务端去掉对预检请求的重定向;将实际请求变成一个简单请求。
如果上面两种方式难以做到,我们仍有其他办法:
使用简单请求模拟预检请求,用以探查预检请求是否重定向到其他 URL(使用 Response.url 或 XHR.responseURL);向上一步中获得的 URL 发起请求。
不过,如果请求由于缺失 Authorization 字段而引起一个预检请求,则这一方法将无法使用。这种情况只能由服务端进行更改。
附带身份凭证的请求
Fetch 与 CORS 的一个有趣的特性是,可以基于 HTTP cookies 和 HTTP 认证信息发送身份凭证。一般而言,对于跨域 XMLHttpRequest 或 Fetch 请求,浏览器不会发送身份凭证信息。如果要发送凭证信息,需要设置 XMLHttpRequest 的某个特殊标志位。
本例中,http://foo.example 的某脚本向 http://bar.other 发起一个GET 请求,并设置 Cookies:var invocation = new XMLHttpRequest();
var url = 'http://bar.other/resources/credentialed-content/';
function callOtherDomain(){
if(invocation) {
invocation.open('GET', url, true);
invocation.withCredentials = true;
invocation.onreadystatechange = handler;
invocation.send();
}
}第 7 行将 XMLHttpRequest 的 withCredentials 标志设置为 true,从而向服务器发送 Cookies。因为这是一个简单 GET 请求,所以浏览器不会对其发起“预检请求”。但是,如果服务器端的响应中未携带 Access-Control-Allow-Credentials: true ,浏览器将不会把响应内容返回给请求的发送者。
客户端与服务器端交互示例如下:GET /resources/access-control-with-credentials/ HTTP/1.1
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Referer: http://foo.example/examples/credential.html
Origin: http://foo.example
Cookie: pageAccess=2
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:34:52 GMT
Server: Apache/2.0.61 (Unix) PHP/4.4.7 mod_ssl/2.0.61 OpenSSL/0.9.7e mod_fastcgi/2.4.2 DAV/2 SVN/1.4.2
X-Powered-By: PHP/5.2.6
Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Credentials: true
Cache-Control: no-cache
Pragma: no-cache
Set-Cookie: pageAccess=3; expires=Wed, 31-Dec-2008 01:34:53 GMT
Vary: Accept-Encoding, Origin
Content-Encoding: gzip
Content-Length: 106
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain
[text/plain payload]即使第 11 行指定了 Cookie 的相关信息,但是,如果 bar.other 的响应中缺失 Access-Control-Allow-Credentials: true(第 19 行),则响应内容不会返回给请求的发起者。
附带身份凭证的请求与通配符
对于附带身份凭证的请求,服务器不得设置 Access-Control-Allow-Origin 的值为“*”。
这是因为请求的首部中携带了 Cookie 信息,如果 Access-Control-Allow-Origin 的值为“*”,请求将会失败。而将 Access-Control-Allow-Origin 的值设置为 http://foo.example,则请求将成功执行。
另外,响应首部中也携带了 Set-Cookie 字段,尝试对 Cookie 进行修改。如果操作失败,将会抛出异常。
HTTP 响应首部字段
本节列出了规范所定义的响应首部字段。上一小节中,我们已经看到了这些首部字段在实际场景中是如何工作的。
Access-Control-Allow-Origin
响应首部中可以携带一个 Access-Control-Allow-Origin 字段,其语法如下:Access-Control-Allow-Origin: <origin> | *其中,origin 参数的值指定了允许访问该资源的外域 URI。对于不需要携带身份凭证的请求,服务器可以指定该字段的值为通配符,表示允许来自所有域的请求。
例如,下面的字段值将允许来自 http://mozilla.com 的请求:Access-Control-Allow-Origin: http://mozilla.com如果服务端指定了具体的域名而非“*”,那么响应首部中的 Vary 字段的值必须包含 Origin。这将告诉客户端:服务器对不同的源站返回不同的内容。
Access-Control-Expose-Headers
译者注:在跨域访问时,XMLHttpRequest对象的getResponseHeader()方法只能拿到一些最基本的响应头,Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma,如果要访问其他头,则需要服务器设置本响应头。
Access-Control-Expose-Headers 头让服务器把允许浏览器访问的头放入白名单,例如:
Access-Control-Expose-Headers: X-My-Custom-Header, X-Another-Custom-Header这样浏览器就能够通过getResponseHeader访问X-My-Custom-Header和 X-Another-Custom-Header 响应头了。
Access-Control-Max-Age
Access-Control-Max-Age 头指定了preflight请求的结果能够被缓存多久,请参考本文在前面提到的preflight例子。
Access-Control-Max-Age: <delta-seconds>delta-seconds 参数表示preflight请求的结果在多少秒内有效。
Access-Control-Allow-Credentials
Access-Control-Allow-Credentials 头指定了当浏览器的credentials设置为true时是否允许浏览器读取response的内容。当用在对preflight预检测请求的响应中时,它指定了实际的请求是否可以使用credentials。请注意:简单 GET 请求不会被预检;如果对此类请求的响应中不包含该字段,这个响应将被忽略掉,并且浏览器也不会将相应内容返回给网页。
Access-Control-Allow-Credentials: true上文已经讨论了附带身份凭证的请求。
Access-Control-Allow-Methods
Access-Control-Allow-Methods 首部字段用于预检请求的响应。其指明了实际请求所允许使用的 HTTP 方法。
Access-Control-Allow-Methods: <method>[, <method>]*相关示例见这里。
Access-Control-Allow-Headers
Access-Control-Allow-Headers 首部字段用于预检请求的响应。其指明了实际请求中允许携带的首部字段。
Access-Control-Allow-Headers: <field-name>[, <field-name>]*
HTTP 请求首部字段
Origin 首部字段表明预检请求或实际请求的源站。
Origin: <origin>origin 参数的值为源站 URI。它不包含任何路径信息,只是服务器名称。
Note: 有时候将该字段的值设置为空字符串是有用的,例如,当源站是一个 data URL 时。
注意,不管是否为跨域请求,ORIGIN 字段总是被发送。
Access-Control-Request-Method
Access-Control-Request-Method 首部字段用于预检请求。其作用是,将实际请求所使用的 HTTP 方法告诉服务器。Access-Control-Request-Method: <method>
Access-Control-Request-Headers
Access-Control-Request-Headers 首部字段用于预检请求。其作用是,将实际请求所携带的首部字段告诉服务器。
Access-Control-Request-Headers: <field-name>[, <field-name>]*
浏览器兼容性
注:
IE 10 提供了对规范的完整支持,但在较早版本(8 和 9)中,CORS 机制是借由 XDomainRequest 对象完成的。Firefox 3.5 引入了对 XMLHttpRequests 和 Web 字体的跨域支持(但最初的实现并不完整,这在后续版本中得到完善);Firefox 7 引入了对 WebGL 贴图的跨域支持;Firefox 9 引入了对 drawImage 的跨域支持。
参考文档:https://developer.mozilla.org/ ... _CORS 查看全部
比如,站点 http://domain-a.com 的某 HTML 页面通过 <img> 的 src 请求 http://domain-b.com/image.jpg。网络上的许多页面都会加载来自不同域的CSS样式表,图像和脚本等资源。
出于安全原因,浏览器限制从脚本内发起的跨源HTTP请求。 例如,XMLHttpRequest和Fetch API遵循同源策略。 这意味着使用这些API的Web应用程序只能从加载应用程序的同一个域请求HTTP资源,除非使用CORS头文件。
(译者注:这段描述跨域不准确,跨域并不一定是浏览器限制了发起跨站请求,也可能是跨站请求可以正常发起,但是返回结果被浏览器拦截了。最好的例子是 CSRF 跨站攻击原理,请求是发送到了后端服务器无论是否跨域!注意:有些浏览器不允许从 HTTPS 的域跨域访问 HTTP,比如 Chrome 和 Firefox,这些浏览器在请求还未发出的时候就会拦截请求,这是一个特例。)

跨域资源共享标准( cross-origin sharing standard )允许在下列场景中使用跨域 HTTP 请求:
- 前文提到的由 XMLHttpRequest 或 Fetch 发起的跨域 HTTP 请求。
- Web 字体 (CSS 中通过 @font-face 使用跨域字体资源), 因此,网站就可以发布 TrueType 字体资源,并只允许已授权网站进行跨站调用。
- WebGL 贴图
- 使用 drawImage 将 Images/video 画面绘制到 canvas
- 样式表(使用 CSSOM)
- Scripts (未处理的异常)
本文概述了跨域资源共享机制及其所涉及的 HTTP 首部字段。
概述
跨域资源共享标准新增了一组 HTTP 首部字段,允许服务器声明哪些源站有权限访问哪些资源。另外,规范要求,对那些可能对服务器数据产生副作用的 HTTP 请求方法(特别是 GET 以外的 HTTP 请求,或者搭配某些 MIME 类型的 POST 请求),浏览器必须首先使用 OPTIONS 方法发起一个预检请求(preflight request),从而获知服务端是否允许该跨域请求。服务器确认允许之后,才发起实际的 HTTP 请求。在预检请求的返回中,服务器端也可以通知客户端,是否需要携带身份凭证(包括 Cookies 和 HTTP 认证相关数据)。
接下来的内容将讨论相关场景,并剖析该机制所涉及的 HTTP 首部字段。
若干访问控制场景
这里,我们使用三个场景来解释跨域资源共享机制的工作原理。这些例子都使用 XMLHttpRequest 对象。
简单请求
某些请求不会触发 CORS 预检请求。本文称这样的请求为“简单请求”,请注意,该术语并不属于 Fetch (其中定义了 CORS)规范。若请求满足所有下述条件,则该请求可视为“简单请求”:
1.使用下列方法之一:
- GET
- HEAD
- POST
2.Fetch 规范定义了对 CORS 安全的首部字段集合,不得人为设置该集合之外的其他首部字段。该集合为:
- Accept
- Accept-Language
- Content-Language
- Content-Type (需要注意额外的限制)
- DPR
- Downlink
- Save-Data
- Viewport-Width
- Width
3.Content-Type 的值仅限于下列三者之一:
- text/plain
- multipart/form-data
- application/x-www-form-urlencoded
比如说,假如站点 http://foo.example 的网页应用想要访问 http://bar.other 的资源。http://foo.example 的网页中可能包含类似于下面的 JavaScript 代码:
var invocation = new XMLHttpRequest();客户端和服务器之间使用 CORS 首部字段来处理跨域权限:
var url = 'http://bar.other/resources/public-data/';
function callOtherDomain() {
if(invocation) {
invocation.open('GET', url, true);
invocation.onreadystatechange = handler;
invocation.send();
}
}

分别检视请求报文和响应报文:
GET /resources/public-data/ HTTP/1.1第 1~10 行是请求首部。第10行 的请求首部字段 Origin 表明该请求来源于 http://foo.exmaple。
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Referer: http://foo.example/examples/ac ... .html
Origin: http://foo.example
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 00:23:53 GMT
Server: Apache/2.0.61
Access-Control-Allow-Origin: *
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Transfer-Encoding: chunked
Content-Type: application/xml
[XML Data]
第 13~22 行是来自于 http://bar.other 的服务端响应。响应中携带了响应首部字段 Access-Control-Allow-Origin(第 16 行)。使用 Origin 和 Access-Control-Allow-Origin 就能完成最简单的访问控制。本例中,服务端返回的 Access-Control-Allow-Origin: * 表明,该资源可以被任意外域访问。如果服务端仅允许来自 http://foo.example 的访问,该首部字段的内容如下:
Access-Control-Allow-Origin: http://foo.example
现在,除了 http://foo.example,其它外域均不能访问该资源(该策略由请求首部中的 ORIGIN 字段定义,见第10行)。Access-Control-Allow-Origin 应当为 * 或者包含由 Origin 首部字段所指明的域名。
预检请求
与前述简单请求不同,“需预检的请求”要求必须首先使用 OPTIONS 方法发起一个预检请求到服务器,以获知服务器是否允许该实际请求。"预检请求“的使用,可以避免跨域请求对服务器的用户数据产生未预期的影响。
当请求满足下述任一条件时,即应首先发送预检请求:
1.使用了下面任一 HTTP 方法:
- PUT
- DELETE
- CONNECT
- OPTIONS
- TRACE
- PATCH
2.人为设置了对 CORS 安全的首部字段集合之外的其他首部字段。该集合为:
- Accept
- Accept-Language
- Content-Language
- Content-Type (but note the additional requirements below)
- DPR
- Downlink
- Save-Data
- Viewport-Width
- Width
3.Content-Type 的值不属于下列之一:
- application/x-www-form-urlencoded
- multipart/form-data
- text/plain
如下是一个需要执行预检请求的 HTTP 请求:
var invocation = new XMLHttpRequest();上面的代码使用 POST 请求发送一个 XML 文档,该请求包含了一个自定义的请求首部字段(X-PINGOTHER: pingpong)。另外,该请求的 Content-Type 为 application/xml。因此,该请求需要首先发起“预检请求”。
var url = 'http://bar.other/resources/post-here/';
var body = '<?xml version="1.0"?><person><name>Arun</name></person>';
function callOtherDomain(){
if(invocation)
{
invocation.open('POST', url, true);
invocation.setRequestHeader('X-PINGOTHER', 'pingpong');
invocation.setRequestHeader('Content-Type', 'application/xml');
invocation.onreadystatechange = handler;
invocation.send(body);
}
}
......

OPTIONS /resources/post-here/ HTTP/1.1预检请求完成之后,发送实际请求:
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Origin: http://foo.example
Access-Control-Request-Method: POST
Access-Control-Request-Headers: X-PINGOTHER, Content-Type
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:15:39 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400
Vary: Accept-Encoding, Origin
Content-Encoding: gzip
Content-Length: 0
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain
POST /resources/post-here/ HTTP/1.1浏览器检测到,从 JavaScript 中发起的请求需要被预检。从上面的报文中,我们看到,第 1~12 行发送了一个使用 OPTIONS 方法的“预检请求”。 OPTIONS 是 HTTP/1.1 协议中定义的方法,用以从服务器获取更多信息。该方法不会对服务器资源产生影响。 预检请求中同时携带了下面两个首部字段:
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
X-PINGOTHER: pingpong
Content-Type: text/xml; charset=UTF-8
Referer: http://foo.example/examples/pr ... .html
Content-Length: 55
Origin: http://foo.example
Pragma: no-cache
Cache-Control: no-cache
<?xml version="1.0"?><person><name>Arun</name></person>
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:15:40 GMT
Server: Apache/2.0.61 (Unix)
Access-Control-Allow-Origin: http://foo.example
Vary: Accept-Encoding, Origin
Content-Encoding: gzip
Content-Length: 235
Keep-Alive: timeout=2, max=99
Connection: Keep-Alive
Content-Type: text/plain
[Some GZIP'd payload]
Access-Control-Request-Method: POST首部字段 Access-Control-Request-Method 告知服务器,实际请求将使用 POST 方法。
Access-Control-Request-Headers: X-PINGOTHER
首部字段 Access-Control-Request-Headers 告知服务器,实际请求将携带两个自定义请求首部字段:X-PINGOTHER 与 Content-Type。
服务器据此决定,该实际请求是否被允许。第14~26 行为预检请求的响应,表明服务器将接受后续的实际请求。重点看第 17~20 行:
Access-Control-Allow-Origin: http://foo.example首部字段 Access-Control-Allow-Methods 表明服务器允许客户端使用 POST, GET 和OPTIONS 方法发起请求。该字段与 HTTP/1.1 Allow: response header 类似,但仅限于在需要访问控制的场景中使用。首部字段 Access-Control-Allow-Headers 表明服务器允许请求中携带字段 X-PINGOTHER 与 Content-Type。与 Access-Control-Allow-Methods 一样,Access-Control-Allow-Headers 的值为逗号分割的列表。
Access-Control-Allow-Methods: POST, GET, OPTIONS
Access-Control-Allow-Headers: X-PINGOTHER, Content-Type
Access-Control-Max-Age: 86400
最后,首部字段 Access-Control-Max-Age 表明该响应的有效时间为 86400 秒,也就是 24 小时。在有效时间内,浏览器无须为同一请求再次发起预检请求。请注意,浏览器自身维护了一个最大有效时间,如果该首部字段的值超过了最大有效时间,将不会生效。
预检请求与重定向
大多数浏览器不支持针对于预检请求的重定向。如果一个预检请求发生了重定向,浏览器将报告错误:
The request was redirected to 'https://example.com/foo', which is disallowed for cross-origin requests that require preflightCORS 最初要求该行为,不过在后续的修订中废弃了这一要求。
Request requires preflight, which is disallowed to follow cross-origin redirect
在浏览器的实现跟上规范之前,有两种方式规避上述报错行为:
- 在服务端去掉对预检请求的重定向;
- 将实际请求变成一个简单请求。
如果上面两种方式难以做到,我们仍有其他办法:
- 使用简单请求模拟预检请求,用以探查预检请求是否重定向到其他 URL(使用 Response.url 或 XHR.responseURL);
- 向上一步中获得的 URL 发起请求。
不过,如果请求由于缺失 Authorization 字段而引起一个预检请求,则这一方法将无法使用。这种情况只能由服务端进行更改。
附带身份凭证的请求
Fetch 与 CORS 的一个有趣的特性是,可以基于 HTTP cookies 和 HTTP 认证信息发送身份凭证。一般而言,对于跨域 XMLHttpRequest 或 Fetch 请求,浏览器不会发送身份凭证信息。如果要发送凭证信息,需要设置 XMLHttpRequest 的某个特殊标志位。
本例中,http://foo.example 的某脚本向 http://bar.other 发起一个GET 请求,并设置 Cookies:
var invocation = new XMLHttpRequest();第 7 行将 XMLHttpRequest 的 withCredentials 标志设置为 true,从而向服务器发送 Cookies。因为这是一个简单 GET 请求,所以浏览器不会对其发起“预检请求”。但是,如果服务器端的响应中未携带 Access-Control-Allow-Credentials: true ,浏览器将不会把响应内容返回给请求的发送者。
var url = 'http://bar.other/resources/credentialed-content/';
function callOtherDomain(){
if(invocation) {
invocation.open('GET', url, true);
invocation.withCredentials = true;
invocation.onreadystatechange = handler;
invocation.send();
}
}

客户端与服务器端交互示例如下:
GET /resources/access-control-with-credentials/ HTTP/1.1即使第 11 行指定了 Cookie 的相关信息,但是,如果 bar.other 的响应中缺失 Access-Control-Allow-Credentials: true(第 19 行),则响应内容不会返回给请求的发起者。
Host: bar.other
User-Agent: Mozilla/5.0 (Macintosh; U; Intel Mac OS X 10.5; en-US; rv:1.9.1b3pre) Gecko/20081130 Minefield/3.1b3pre
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Language: en-us,en;q=0.5
Accept-Encoding: gzip,deflate
Accept-Charset: ISO-8859-1,utf-8;q=0.7,*;q=0.7
Connection: keep-alive
Referer: http://foo.example/examples/credential.html
Origin: http://foo.example
Cookie: pageAccess=2
HTTP/1.1 200 OK
Date: Mon, 01 Dec 2008 01:34:52 GMT
Server: Apache/2.0.61 (Unix) PHP/4.4.7 mod_ssl/2.0.61 OpenSSL/0.9.7e mod_fastcgi/2.4.2 DAV/2 SVN/1.4.2
X-Powered-By: PHP/5.2.6
Access-Control-Allow-Origin: http://foo.example
Access-Control-Allow-Credentials: true
Cache-Control: no-cache
Pragma: no-cache
Set-Cookie: pageAccess=3; expires=Wed, 31-Dec-2008 01:34:53 GMT
Vary: Accept-Encoding, Origin
Content-Encoding: gzip
Content-Length: 106
Keep-Alive: timeout=2, max=100
Connection: Keep-Alive
Content-Type: text/plain
[text/plain payload]
附带身份凭证的请求与通配符
对于附带身份凭证的请求,服务器不得设置 Access-Control-Allow-Origin 的值为“*”。
这是因为请求的首部中携带了 Cookie 信息,如果 Access-Control-Allow-Origin 的值为“*”,请求将会失败。而将 Access-Control-Allow-Origin 的值设置为 http://foo.example,则请求将成功执行。
另外,响应首部中也携带了 Set-Cookie 字段,尝试对 Cookie 进行修改。如果操作失败,将会抛出异常。
HTTP 响应首部字段
本节列出了规范所定义的响应首部字段。上一小节中,我们已经看到了这些首部字段在实际场景中是如何工作的。
Access-Control-Allow-Origin
响应首部中可以携带一个 Access-Control-Allow-Origin 字段,其语法如下:
Access-Control-Allow-Origin: <origin> | *其中,origin 参数的值指定了允许访问该资源的外域 URI。对于不需要携带身份凭证的请求,服务器可以指定该字段的值为通配符,表示允许来自所有域的请求。
例如,下面的字段值将允许来自 http://mozilla.com 的请求:
Access-Control-Allow-Origin: http://mozilla.com如果服务端指定了具体的域名而非“*”,那么响应首部中的 Vary 字段的值必须包含 Origin。这将告诉客户端:服务器对不同的源站返回不同的内容。
Access-Control-Expose-Headers
译者注:在跨域访问时,XMLHttpRequest对象的getResponseHeader()方法只能拿到一些最基本的响应头,Cache-Control、Content-Language、Content-Type、Expires、Last-Modified、Pragma,如果要访问其他头,则需要服务器设置本响应头。
Access-Control-Expose-Headers 头让服务器把允许浏览器访问的头放入白名单,例如:
Access-Control-Expose-Headers: X-My-Custom-Header, X-Another-Custom-Header这样浏览器就能够通过getResponseHeader访问X-My-Custom-Header和 X-Another-Custom-Header 响应头了。
Access-Control-Max-Age
Access-Control-Max-Age 头指定了preflight请求的结果能够被缓存多久,请参考本文在前面提到的preflight例子。
Access-Control-Max-Age: <delta-seconds>delta-seconds 参数表示preflight请求的结果在多少秒内有效。
Access-Control-Allow-Credentials
Access-Control-Allow-Credentials 头指定了当浏览器的credentials设置为true时是否允许浏览器读取response的内容。当用在对preflight预检测请求的响应中时,它指定了实际的请求是否可以使用credentials。请注意:简单 GET 请求不会被预检;如果对此类请求的响应中不包含该字段,这个响应将被忽略掉,并且浏览器也不会将相应内容返回给网页。
Access-Control-Allow-Credentials: true上文已经讨论了附带身份凭证的请求。
Access-Control-Allow-Methods
Access-Control-Allow-Methods 首部字段用于预检请求的响应。其指明了实际请求所允许使用的 HTTP 方法。
Access-Control-Allow-Methods: <method>[, <method>]*相关示例见这里。Access-Control-Allow-Headers
Access-Control-Allow-Headers 首部字段用于预检请求的响应。其指明了实际请求中允许携带的首部字段。
Access-Control-Allow-Headers: <field-name>[, <field-name>]*HTTP 请求首部字段
Origin 首部字段表明预检请求或实际请求的源站。
Origin: <origin>origin 参数的值为源站 URI。它不包含任何路径信息,只是服务器名称。
Note: 有时候将该字段的值设置为空字符串是有用的,例如,当源站是一个 data URL 时。
注意,不管是否为跨域请求,ORIGIN 字段总是被发送。
Access-Control-Request-Method
Access-Control-Request-Method 首部字段用于预检请求。其作用是,将实际请求所使用的 HTTP 方法告诉服务器。
Access-Control-Request-Method: <method>
Access-Control-Request-Headers
Access-Control-Request-Headers 首部字段用于预检请求。其作用是,将实际请求所携带的首部字段告诉服务器。
Access-Control-Request-Headers: <field-name>[, <field-name>]*浏览器兼容性


注:
- IE 10 提供了对规范的完整支持,但在较早版本(8 和 9)中,CORS 机制是借由 XDomainRequest 对象完成的。
- Firefox 3.5 引入了对 XMLHttpRequests 和 Web 字体的跨域支持(但最初的实现并不完整,这在后续版本中得到完善);Firefox 7 引入了对 WebGL 贴图的跨域支持;Firefox 9 引入了对 drawImage 的跨域支持。
参考文档:https://developer.mozilla.org/ ... _CORS
JS获取页面URL数据的集中方式整理
前端开发 • zkbhj 发表了文章 • 0 个评论 • 3216 次浏览 • 2017-11-22 10:50
设置或获取整个 URL 为字符串。 alert(window.location.href);
设置或获取与 URL 关联的端口号码。alert(window.location.port)
设置或获取 URL 的协议部分。alert(window.location.protocol)
设置或获取 href 属性中在井号“#”后面的分段。alert(window.location.hash)
设置或获取 location 或 URL 的 hostname 和 port 号码。alert(window.location.host)
设置或获取 href 属性中跟在问号后面的部分。alert(window.location.search)
获取变量的值(截取等号后面的部分)var url = window.location.search;
// alert(url.length);
// alert(url.lastIndexOf('='));
var loc = url.substring(url.lastIndexOf('=')+1, url.length); 查看全部
alert(window.location.pathname)
设置或获取整个 URL 为字符串。
alert(window.location.href);
设置或获取与 URL 关联的端口号码。
alert(window.location.port)
设置或获取 URL 的协议部分。
alert(window.location.protocol)
设置或获取 href 属性中在井号“#”后面的分段。
alert(window.location.hash)
设置或获取 location 或 URL 的 hostname 和 port 号码。
alert(window.location.host)
设置或获取 href 属性中跟在问号后面的部分。
alert(window.location.search)
获取变量的值(截取等号后面的部分)
var url = window.location.search;
// alert(url.length);
// alert(url.lastIndexOf('='));
var loc = url.substring(url.lastIndexOf('=')+1, url.length);